Node*merges(Node*x) {if (x==nullptr||x->sibling==nullptr)returnx;// 如果该树为空或他没有下一个兄弟,就不需要合并了,return。Node*y=x->sibling;// y 为 x 的下一个兄弟Node*c=y->sibling;// c 是再下一个兄弟x->sibling=y->sibling=nullptr;// 拆散returnmeld(merges(c),meld(x,y));// 核心部分}
The limitations of traditional binary search trees can be frustrating. Meet the B-Tree, the multi-talented data structure that can handle massive amounts of data with ease. When it comes to storing and searching large amounts of data, traditional binary search trees can become impractical due to their poor performance and high memory usage. B-Trees, also known as B-Tree or Balanced Tree, are a type of self-balancing tree that was specifically designed to overcome these limitations.
properties
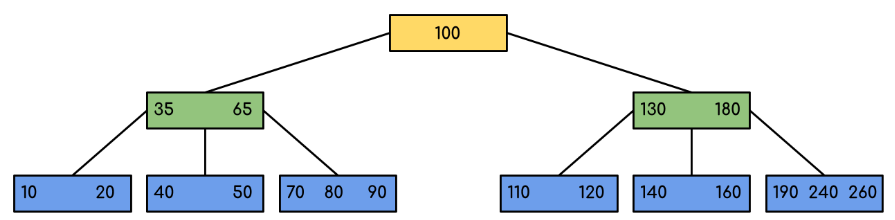
~Every node except the root must contain at most t-1 keys. The root may contain a minimum of 1 key. ~All nodes (including root) may contain at most (2*t – 1) keys ~B-Tree grows and shrinks from the root which is unlike Binary Search Tree. Binary Search Trees grow downward and also shrink from downward.
Traversal in B-Tree:
Traversal is also similar to Inorder traversal of Binary Tree. We start from the leftmost child, recursively print the leftmost child, then repeat the same process for the remaining children and keys. In the end, recursively print the rightmost child.
Search Operation in B-Tree:
Search is similar to the search in Binary Search Tree. Let the key to be searched is k.
Start from the root and recursively traverse down.
For every visited non-leaf node,
If the node has the key, we simply return the node.
Otherwise, we recur down to the appropriate child (The child which is just before the first greater key) of the node.
If we reach a leaf node and don’t find k in the leaf node, then return NULL.
Searching a B-Tree is similar to searching a binary tree. The algorithm is similar and goes with recursion. At each level, the search is optimized as if the key value is not present in the range of the parent then the key is present in another branch. As these values limit the search they are also known as limiting values or separation values. If we reach a leaf node and don’t find the desired key then it will display NULL.
Insert Operation in B-Tree
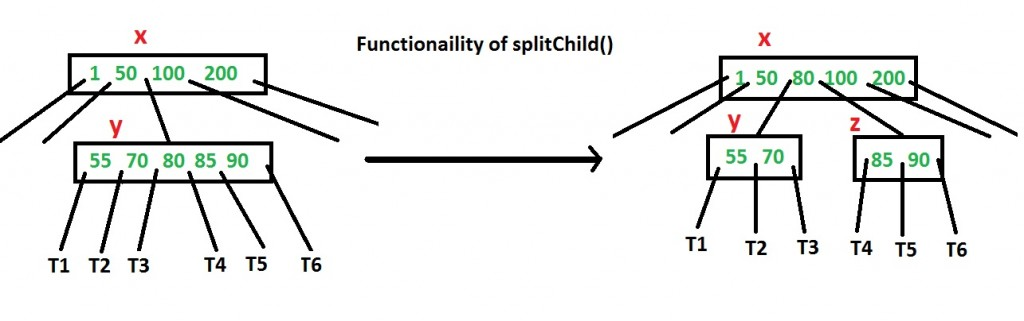
How to make sure that a node has space available for a key before the key is inserted? We use an operation called splitChild() that is used to split a child of a node. See the following diagram to understand split. In the following diagram, child y of x is being split into two nodes y and z. Note that the splitChild operation moves a key up and this is the reason B-Trees grow up, unlike BSTs which grow down.
Insertion 1) Initialize x as root. 2) While x is not leaf, do following ..a) Find the child of x that is going to be traversed next. Let the child be y. ..b) If y is not full, change x to point to y. ..c) If y is full, split it and change x to point to one of the two parts of y. If k is smaller than mid key in y, then set x as the first part of y. Else second part of y. When we split y, we move a key from y to its parent x. 3) The loop in step 2 stops when x is leaf. x must have space for 1 extra key as we have been splitting all nodes in advance. So simply insert k to x.
针对一棵高度为 h 的 m阶 B 树,插入一个元素时,首先要验证该元素在 B 树中是否存在,如果不存在,那么就要在叶子节点中插入该新的元素,此时分 3 种情况:
// C++ program for B-Tree insertion#include<iostream>usingnamespacestd;// A BTree nodeclassBTreeNode{int*keys; // An array of keysint t; // Minimum degree (defines the range for number of keys) BTreeNode **C; // An array of child pointersint n; // Current number of keysbool leaf; // Is true when node is leaf. Otherwise falsepublic:BTreeNode(int_t,bool_leaf); // Constructor // A utility function to insert a new key in the subtree rooted with // this node. The assumption is, the node must be non-full when this // function is calledvoidinsertNonFull(intk); // A utility function to split the child y of this node. i is index of y in // child array C[]. The Child y must be full when this function is calledvoidsplitChild(inti,BTreeNode*y); // A function to traverse all nodes in a subtree rooted with this nodevoidtraverse(); // A function to search a key in the subtree rooted with this node.BTreeNode*search(intk); // returns NULL if k is not present.// Make BTree friend of this so that we can access private members of this// class in BTree functionsfriendclassBTree;};// A BTreeclassBTree{ BTreeNode *root; // Pointer to root nodeint t; // Minimum degreepublic: // Constructor (Initializes tree as empty)BTree(int_t){ root =NULL; t = _t;} // function to traverse the treevoidtraverse(){if(root !=NULL)root->traverse();} // function to search a key in this treeBTreeNode*search(intk){return(root ==NULL)?NULL:root->search(k);} // The main function that inserts a new key in this B-Treevoidinsert(intk);};// Constructor for BTreeNode classBTreeNode::BTreeNode(int t1,bool leaf1){ // Copy the given minimum degree and leaf property t = t1; leaf = leaf1; // Allocate memory for maximum number of possible keys // and child pointers keys =newint[2*t-1]; C =new BTreeNode *[2*t]; // Initialize the number of keys as 0 n =0;}// Function to traverse all nodes in a subtree rooted with this nodevoidBTreeNode::traverse(){ // There are n keys and n+1 children, traverse through n keys // and first n childrenint i;for(i =0; i < n; i++){ // If this is not leaf, then before printing key[i], // traverse the subtree rooted with child C[i].if(leaf ==false)C[i]->traverse(); cout <<""<<keys[i];} // Print the subtree rooted with last childif(leaf ==false) C[i]->traverse();}// Function to search key k in subtree rooted with this nodeBTreeNode*BTreeNode::search(intk){ // Find the first key greater than or equal to kint i =0;while(i < n && k > keys[i]) i++; // If the found key is equal to k, return this nodeif(keys[i]== k)returnthis; // If key is not found here and this is a leaf nodeif(leaf ==true)returnNULL; // Go to the appropriate childreturn C[i]->search(k);}// The main function that inserts a new key in this B-TreevoidBTree::insert(intk){ // If tree is emptyif(root ==NULL){ // Allocate memory for root root =newBTreeNode(t,true);root->keys[0]= k; // Insert keyroot->n=1; // Update number of keys in root}else // If tree is not empty{ // If root is full, then tree grows in heightif(root->n==2*t-1){ // Allocate memory for new root BTreeNode *s =newBTreeNode(t,false); // Make old root as child of new roots->C[0]= root; // Split the old root and move 1 key to the new roots->splitChild(0, root); // New root has two children now. Decide which of the // two children is going to have new keyint i =0;if(s->keys[0]< k) i++;s->C[i]->insertNonFull(k); // Change root root = s;}else // If root is not full, call insertNonFull for rootroot->insertNonFull(k);}}// A utility function to insert a new key in this node// The assumption is, the node must be non-full when this// function is calledvoidBTreeNode::insertNonFull(intk){ // Initialize index as index of rightmost elementint i = n-1; // If this is a leaf nodeif(leaf ==true){ // The following loop does two things // a) Finds the location of new key to be inserted // b) Moves all greater keys to one place aheadwhile(i >=0&&keys[i]> k){keys[i+1]=keys[i]; i--;} // Insert the new key at found locationkeys[i+1]= k; n = n+1;}else // If this node is not leaf{ // Find the child which is going to have the new keywhile(i >=0&&keys[i]> k) i--; // See if the found child is fullif(C[i+1]->n==2*t-1){ // If the child is full, then split itsplitChild(i+1,C[i+1]); // After split, the middle key of C[i] goes up and // C[i] is splitted into two. See which of the two // is going to have the new keyif(keys[i+1]< k) i++;}C[i+1]->insertNonFull(k);}}// A utility function to split the child y of this node// Note that y must be full when this function is calledvoidBTreeNode::splitChild(inti,BTreeNode*y){ // Create a new node which is going to store (t-1) keys // of y BTreeNode *z =newBTreeNode(y->t, y->leaf); z->n = t -1; // Copy the last (t-1) keys of y to zfor(int j =0; j < t-1; j++) z->keys[j]= y->keys[j+t]; // Copy the last t children of y to zif(y->leaf ==false){for(int j =0; j < t; j++)z->C[j]=y->C[j+t];} // Reduce the number of keys in y y->n = t -1; // Since this node is going to have a new child, // create space of new childfor(int j = n; j >= i+1; j--) C[j+1]= C[j]; // Link the new child to this node C[i+1]= z; // A key of y will move to this node. Find the location of // new key and move all greater keys one space aheadfor(int j = n-1; j >= i; j--) keys[j+1]= keys[j]; // Copy the middle key of y to this node keys[i]= y->keys[t-1]; // Increment count of keys in this node n = n +1;}// Driver program to test above functionsintmain(){ BTree t(3); // A B-Tree with minimum degree 3 t.insert(10); t.insert(20); t.insert(5); t.insert(6); t.insert(12); t.insert(30); t.insert(7); t.insert(17); cout <<"Traversal of the constructed tree is "; t.traverse();int k =6;(t.search(k)!=NULL)? cout <<"\nPresent": cout <<"\nNot Present"; k =15;(t.search(k)!=NULL)? cout <<"\nPresent": cout <<"\nNot Present";return0;}








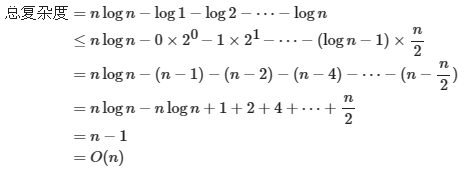


,则直接插入在叶子节点的左边或右边;
m个,则需要将该节点进行「分裂」,将一半数量的关键字元素分裂到新的其相邻右节点中,中间关键字元素上移到父节点中,而且当节点中关键元素向右移动了,相关的指针也需要向右移。
