
C++ KEY POINTS(NJU SE 2024)
Contents
主题一:资源管理释放与构造析构
new delete
频繁调用系统的存储管理,会影响效率
交由程序自身管理内存,提高效率
方法:
调用系统存储分配,申请一块较大的内存,针对该内存,自己管理存储分配、去配(类似一种内存池的方法)
通过重载 new 与 delete 来实现
重载的 new 和 delete 是静态成员
重载的 new 和 delete 遵循类的访问控制,可继承
重载new:
void *operator new (size_t size, …)new的重载可以有多个
如果重载了new,那么通过new动态创建该类的对象时将不再调用内置的(预定义的)new
重载delete:
void operator delete(void *p, size_t size)第一个参数是被撤销对象的地址,第二个参数是大小
delete的重载只能有一个
#include <iostream>
#include <cstdlib>
// 全局重载 new
void* operator new(size_t size) {
std::cout << "Custom new: Allocating " << size << " bytes\n";
void* ptr = std::malloc(size);
if (!ptr) throw std::bad_alloc();
return ptr;
}
// 全局重载 delete
void operator delete(void* ptr) noexcept {
std::cout << "Custom delete: Freeing memory\n";
std::free(ptr);
}
int main() {
int* p = new int(42); // 调用自定义 new
delete p; // 调用自定义 delete
return 0;
}注意,new int[size]这样的应该针对new[]进行重载才有效
动态变量(from结构化编程 | Co-rricula)
在 C++ 中,除了从 C 继承过来的 malloc 和 free,还可以用 new 和 delete 来生成和回收动态变量。
int *p = new int[8]; // int *p = (int *)malloc(sizeof(int) * 8)
delete[] p; //free(p)当 new 时使用了 [],那么需要在释放时也应当使用。对于申请得来的指针,切勿轻易移动它,防止在 delete 时出现问题。(比如此时delete[] p是OK的,但是p++之后,就是错误的)
new 和 malloc 最大的区别是,当生成的是类的实例时,new 会自动调用类的构造函数(如果生成的是数组,则逐个调用);delete 也同理,它会自动调用类的析构函数,而 delete [] 则可以逐个调用数组的析构函数。
使用指针需要时刻注意严禁出现空闲指针,并谨防内存泄露;
智能指针
(原理实现)
temple<typename T>
class SharedPtr {
public:
SharedPtr() : _ptr((T *)0), _refCount(0){}
SharedPtr(T *obj) : _ptr(obj), _refCount(new int(1)){}
SharedPtr(SharedPtr &other) : _ptr(other._ptr), _refCount(&(++*other._refCount)){}
~SharedPtr(){
if (_ptr && --*_refCount == 0) {
delete _ptr;
delete _refCount;
}
}
SharedPtr &operator=(SharedPtr &other){
if(this==&other)
return *this;
//新指针引用计数要++
++*other._refCount;
//原指针引用计数要--,如果为0,则释放空间
if (--*_refCount == 0) {
delete _ptr;
delete _refCount;
}
//重新进行指向
_ptr = other._ptr;
_refCount = other._refCount;
return *this;
}
T &operator*(){
if (_refCount == 0)
return (T*)0;
return *_ptr;
}
T *operator->(){
if(_refCount == 0)
return 0;
return _ptr;
}
private:
T *_ptr;
int *_refCount; //这里使用int型指针是为了保证拷贝构造时同一个地址空间的引用计数增加
};
构造函数
与类同名、无返回类型
自动调用,不可直接调用
可重载(创建类时如无重载,则有默认构造函数)
class MyClass {
public:
MyClass(int x) { // 带参数的构造函数
// 构造函数实现
}
};
int main() {
MyClass obj(10); // 正确,调用带参数的构造函数
MyClass obj2; // 错误,默认构造函数不存在
return 0;
}默认构造函数
无参数
无参数的默认构造函数意味着它不需要任何额外的信息就能创建对象。这使得它在很多情况下
都能被自动调用
当类中未提供构造函数时,编译系统提供
一旦自定义构造函数,不再提供默认构造函数
可用=default启用
class MyClass {
public:
MyClass() = default; // 让编译器生成默认构造函数
MyClass(int x) { // 带参数的构造函数
// 构造函数实现
}
};
int main() {
MyClass obj1; // 正确,调用默认构造函数
MyClass obj2(10); // 正确,调用带参数的构造函数
return 0;
}常为public,也可定义为private,用于以下情况:
单例模式 (为了防止外部直接创建类的实例)
工厂模式 (必须通过工厂方法来创建实例)
有时,一个类可能不打算被直接实例化,而是作为基类或用于其他目的
实现不可变类
控制对象生命周期:在某些情况下,对象的创建和销毁需要特定的控制。通过将构造函
数设为私有,类可以控制其对象的创建
重载构造

初始化表
即:方式的语法糖,先于构造函数体执行——减轻compiler负担
按类数据成员申明次序:初始化顺序是按照成员变量在类中声明的顺序,而不是按照初始化表中的顺序
就是你自己写的初始化顺序是没用的,不要用后声明的成员变量赋值先声明的在构造函数中尽量使用成员初始化表取代赋值动作
const 成员/reference 成员/对象成员 (常量成员或引用成员必须在声明时或在构造函数的成员初始化表中初始化)
效率高
数据成员太多是不采用本条原则(降低可维护性)
ClassName::ClassName(参数列表) : 成员变量1(初始值1), 成员变量2(初始值2), ... {
// 构造函数体
}析构函数
对象消亡时,系统自动调用
什么情况定义为private:阻止外部销毁,如单例模式
资源管理类:例如智能指针,确保资源只能通过特定的接口释放(强制自主控制对象存储分配)
基类析构函数:如果基类不应该是可实例化的,可以将其析构函数设为private

对于父类子类的析构函数,需要使用虚析构函数,并在子类重写。如果有需要析构的动态数组,请重写实现。
#include <iostream>
class Base {
public:
virtual ~Base() { // 虚析构函数
std::cout << "Base destructor\n";
}
};
class Derived : public Base {
public:
~Derived() {
std::cout << "Derived destructor\n";
}
};
int main() {
Base* ptr = new Derived(); // 基类指针指向派生类对象
delete ptr; // 调用 Derived 和 Base 的析构函数
return 0;
}如果不这样,如下
#include <iostream>
class Base {
public:
~Base() { // 基类析构函数不是虚函数
std::cout << "Base destructor\n";
}
};
class Derived : public Base {
public:
Derived() {
data = new int[100]; // 动态分配内存
std::cout << "Derived constructor\n";
}
~Derived() {
delete[] data; // 释放内存
std::cout << "Derived destructor\n";
}
private:
int* data;
};
int main() {
Base* ptr = new Derived(); // 基类指针指向派生类对象
delete ptr; // 只调用 Base 的析构函数
return 0;
}Derived constructor
Base destructor这样会导致内存泄漏
拷贝构造函数
A(const A &a);创建对象时,用一同类的对象对其初始化
自动调用
注:如果此处不使用引用,就对参数进行了一次值拷贝,就循环调用了具体一些可以这么讲:一个对象需要以值方式传递时,编译器会生成代码调用它的拷贝构造函数以生成一个副本。如果类A的拷贝构造函数是以值方式传递的话,当需要调用类A的拷贝构造函数时,需要以值方式传进一个A的对象作为实参;而以值方式传递需要调用类A的拷贝构造函数;结果就是调用类A的拷贝构造函数导致又一次调用类A的拷贝构造函数,这就是一个无限递归。
默认拷贝构造函数
逐个成员初始化,对于对象成员则是递归进行,重载将取消默认拷贝,或者使用=delete取消默认拷贝构造函数
必要性
如果我们不自定义拷贝构造函数,很容易导致不同对象指向相同的一块内存,不便于内存管理
需要自定义拷贝函数,完成深拷贝
除此以外,还有静态成员的问题
class MyClass {
private:
int* data;
public:
MyClass(int size) {
data = new int[size]; // 动态分配内存
}
~MyClass() {
delete[] data; // 释放内存
}
};
int main() {
MyClass obj1(10);
MyClass obj2 = obj1; // 默认拷贝构造函数,浅拷贝
// obj1 和 obj2 的 data 指针指向同一块内存
// 程序结束时,obj1 和 obj2 都会尝试释放同一块内存,导致崩溃
return 0;
}自定义拷贝构造函数
对于没有定义拷贝行为的成员,调用成员对象的默认构造函数,而不会调用成员对象的默认拷
贝函数
(这一行为是由于,C希望程序员自定义拷贝构造函数后,完全接管对象的构造)
如果自定义构造函数或者拷贝构造函数,要记得处理每个成员,不然编译器会认为你不想管理
解释:
class Member {
public:
Member() {
std::cout << "Member默认构造函数\n";
}
Member(const Member&) {
std::cout << "Member拷贝构造函数\n";
}
};
class MyClass {
private:
Member mem;
public:
MyClass() {
std::cout << "MyClass默认构造函数\n";
}
// 自定义拷贝构造函数
MyClass(const MyClass& other) {
std::cout << "MyClass自定义拷贝构造函数\n";
}
};
int main() {
MyClass obj1; // 调用 MyClass 的默认构造函数
MyClass obj2 = obj1; // 调用 MyClass 的自定义拷贝构造函数
return 0;
}输出:
Member默认构造函数
MyClass默认构造函数
Member默认构造函数
MyClass自定义拷贝构造函数class Member {
public:
Member() {
std::cout << "Member默认构造函数\n";
}
Member(const Member&) {
std::cout << "Member拷贝构造函数\n";
}
};
class MyClass {
private:
Member mem;
public:
MyClass() {
std::cout << "MyClass默认构造函数\n";
}
// 自定义拷贝构造函数,显式调用 Member 的拷贝构造函数
MyClass(const MyClass& other) : mem(other.mem) {
std::cout << "MyClass自定义拷贝构造函数\n";
}
};
int main() {
MyClass obj1; // 调用 MyClass 的默认构造函数
MyClass obj2 = obj1; // 调用 MyClass 的自定义拷贝构造函数
return 0;
}输出:
Member默认构造函数
MyClass默认构造函数
Member拷贝构造函数
MyClass自定义拷贝构造函数总结
- 如果你自定义了拷贝构造函数,编译器会认为你希望完全接管对象的构造过程。
- 对于类中的成员变量,如果你没有在自定义拷贝构造函数中显式地指定它们的拷贝行为,编译器会调用它们的默认构造函数,而不是拷贝构造函数。
- 如果你希望调用成员变量的拷贝构造函数,需要在自定义拷贝构造函数的初始化列表中显式指定。
移动构造函数
A(A a);
只接受右值
直接把一个临时的右值交给一个左值管理(记得把原来的置为空)
由于这个右值马上就要消亡了(不过事实上不止是那么简单),所以直接将引用交给左值就
行,不需要再进行深拷贝,优化大对象的拷贝问题(例如vector扩容时可以直接移动,不需
要重新赋值)
注意,一个右值引用作为参数传进后,此时的右值就成了一个左值,不能继续作为右值引用,
传递给参数中含右值引用的函数
左值要作为右值使用: std move
当右值引用作为参数传递到函数中时,它本身是一个左值。这是因为右值引用是一个具名的变量,而具名的变量是左值。
class A {
private:
int* data;
public:
// 默认构造函数
A() : data(new int[100]) {
std::cout << "默认构造函数\n";
}
// 移动构造函数
A(A&& other) noexcept : data(other.data) {
std::cout << "移动构造函数\n";
other.data = nullptr; // 将原对象的指针置为空
}
// 析构函数
~A() {
delete[] data;
}
};std::vector<std::string> vec1 = {"a", "b", "c"};
std::vector<std::string> vec2 = std::move(vec1); // 移动语义,避免复制移动语义特别适合优化大对象的拷贝问题,例如 std::vector 扩容时直接移动数据,而不是复制。
因此实现移动构造函数时候需要注意将原资源的对象置为空,否则会出现以下问题:
class A {
private:
int* data;
public:
A() : data(new int[100]) {}
// 移动构造函数(未将原对象的指针置为空)
A(A&& other) noexcept : data(other.data) {}
~A() {
delete[] data;
}
};
int main() {
A a1;
A a2 = std::move(a1); // 移动语义
// a1 和 a2 共享同一块内存
// 程序结束时,a1 和 a2 都会尝试释放同一块内存,导致崩溃
return 0;
}只有以下操作才是符合移动语义的:
class A {
private:
int* data;
public:
A() : data(new int[100]) {}
// 移动构造函数
A(A&& other) noexcept : data(other.data) {
other.data = nullptr; // 将原对象的指针置为空
}
~A() {
delete[] data;
}
void useData() {
if (data) {
std::cout << "Using data\n";
} else {
std::cout << "Data is nullptr\n";
}
}
};
int main() {
A a1;
A a2 = std::move(a1); // 移动语义
a1.useData(); // 输出:Data is nullptr
a2.useData(); // 输出:Using data
return 0;
}为什么要引入new/delete操作符
使得constructor和destructor可以被正确调用
malloc不调用构造函数,free不调用析构函数
动态对象数组
A *p;
p = new A[100];
delete []p;delete []p ([]不能省) (原理是使用了额外的四个字节来确定数组长度)
注意: 不能显式初始化,相应的类必须有默认构造函数
成员函数
class A
{
int x,y;
public:
void show() const;
}const成员函数可以被对应的具有相同形参列表的非const成员函数重载
在这种情况下,类对象的常量性决定调用哪一个函数:
const成员函数可以访问非const对象的非const数据成员,const数据成员,也可以访问const对象内的所有数据成员;
非const成员函数只可以访问非const对象的任意的数据成员,不能访问const对象的任意数据成员
class MyClass {
public:
void func() {
std::cout << "非 const 成员函数\n";
}
void func() const {
std::cout << "const 成员函数\n";
}
};
int main() {
MyClass obj1;
const MyClass obj2;
obj1.func(); // 调用非 const 成员函数
obj2.func(); // 调用 const 成员函数
return 0;
}void show() const 其实是 void show(const A* const this)
即const修饰的其实是类的this指针
注意:如果类中存在指针类型的数据成员即便是const函数只能保证不修改该指针的值,并不
能保证不修改指针指向的对象

静态成员
同一个类的不同对象如何共享变量?
放在全局数据区可以共享,但缺乏数据保护,同时会导致名污染 How to do?
静态成员其实就是全局变量和全局函数,但带有访问控制
遵循类访问控制
一定要在类外进行定义
静态成员函数:只能存取静态成员变量,调用静态成员函数,遵循类访问控制
class MyClass {
public:
static int count; // 静态数据成员
static void printCount() { // 静态成员函数
std::cout << "Count: " << count << "\n";
}
};
int MyClass::count = 0; // 静态数据成员初始化
int main() {
MyClass obj1;
MyClass obj2;
MyClass::printCount(); // 通过类名调用静态成员函数
obj1.printCount(); // 通过对象调用静态成员函数
return 0;
}友元

注意:友元不具有传递性
如果一个函数是多个类的友元,这些类之间并不会互相成为对方的友元。每个类的友元关系都
是独立声明的,不会自动扩展到其他类。
友元函数
友元类是一个类,其所有成员函数都可以访问另一个类的私有和保护成员
友元函数的特点
- 非成员函数:友元函数不是类的成员函数,但它可以访问类的私有和保护成员。
- 声明方式:在类中使用
friend关键字声明友元函数。 - 访问权限:友元函数可以访问类的所有成员,包括私有和保护成员。
- 调用方式:友元函数与普通函数一样调用,不需要通过对象或类名。
class ClassName {
friend ReturnType FunctionName(Parameters); // 友元函数声明
};#include <iostream>
class MyClass {
private:
int x;
public:
MyClass(int value) : x(value) {}
// 声明友元函数
friend void printX(const MyClass& obj);
};
// 定义友元函数
void printX(const MyClass& obj) {
std::cout << "x: " << obj.x << "\n"; // 访问私有成员 x
}
int main() {
MyClass obj(10);
printX(obj); // 调用友元函数
return 0;
}- 操作符重载:友元函数常用于重载操作符,特别是当操作符的左操作数不是类的对象时。
- 工具函数:当某个函数需要访问类的私有成员,但不适合作为类的成员函数时,可以使用友元函数。
- 跨类访问:友元函数可以访问多个类的私有成员,用于实现类之间的协作。
#include <iostream>
class Point {
private:
int x, y;
public:
Point(int x, int y) : x(x), y(y) {}
// 声明友元函数,用于重载 << 操作符
friend std::ostream& operator<<(std::ostream& os, const Point& p);
};
// 定义友元函数
std::ostream& operator<<(std::ostream& os, const Point& p) {
os << "(" << p.x << ", " << p.y << ")";
return os;
}
int main() {
Point p(3, 4);
std::cout << p << "\n"; // 输出:(3, 4)
return 0;
}构造顺序
单个对象创建时构造函数的调用顺序:
- 调用父类的构造函数。
- 调用成员变量的构造函数(调用顺序与声明顺序相同)。
- 调用自身的构造函数。
析构函数与对应构造函数的调用顺序相反。
多个对象析构时,析构顺序与构造顺序相反。
对于析构总结如下:
- 对于栈对象和全局对象,类似于入栈与出栈的顺序,最后构造的对象最先被析构。
- 堆对象的析构发生在使用delete的时候,与delete的使用顺序相关。
主题二:C++史学
C VS C++
- 超集
- C++支持 C 所支持的全部编程技巧
- 任何 C 程序都能被 C++ 用基本相同的方法编写,并具备同等开销(时间、空间)
Bjarne Stroustrup在 1979 年开始开发 C++,最初称为“C with Classes”。C++ 是一种面向对象的编程语言,结合了 C 语言的高效性和面向对象编程的灵活性。再后来他也积极参与 C++ 的 ANSI/ISO 标准化工作
John Backus是FORTRAN的发明人,创建出函数式编程的范式以及BNF范式
设计理念:效率、实用性优于艺术性严谨性、相信程序员
演化历程:
Father of Simular67:Kristen Nygaard
Father of OO:Ole-Johan Dahl
C语言之父:Dennis Ritchie、Ken Thompson
1980形成 C with class:Bjarne Stroustrup
1983年,Rick Mascitti正式命名C++。
结构化编程:Dijkstra 1994制定ANSI C++标准草案
Simula 67 的主要贡献
- 类和对象:Simula 67 引入了类和对象的概念,使得程序可以通过对象来建模和模拟现实世界中的事物。这一概念成为后续面向对象编程语言的基础。
- 继承:Simula 67 支持继承机制,允许类之间共享和重用代码。这一特性极大地提高了代码的可维护性和可扩展性。
- 虚拟过程:Simula 67 引入了虚拟过程(virtual procedures),允许子类重写父类的方法,从而实现多态性。
- 协程:Simula 67 支持协程(coroutines),使得程序可以在多个执行点之间切换,从而实现更复杂的控制流。
- 垃圾回收:Simula 67 包含垃圾回收机制,自动管理内存分配和释放,减少了内存泄漏的风险。
Programming Paradigm(编程方法)
Functional
assume you have lots of little helper functions that interests in synthesizing one large result
Lisp/Scheme/Erlang/Haskell
Logical
Automatic proofs within artificial intelligence
Based on axioms, inference rules, and queries
prolog

C 和 C++混合编程应该注意的问题
(1)名变换:若要调⽤C语⾔库中的函数,要附加关键字“extern “C” ”;按照 C 语⾔⽅式编译和连接,限制
C++编译器做 name mangling(名变换),确保 C++和 C 编译器产⽣兼容的 obj ⽂件;
(2)静态初始化:C++静态的类对象和定义在全局的、命名空间中的或⽂件体中 的类对象的构造函数通常
在 main 被执⾏前就被调⽤,只要可能,⽤ C++写 main(),即使要⽤ C 写 Main 也⽤ C++写;
(3)内存动态分配:new/delete 调⽤ C++的函数库,malloc/free 调⽤ C 的函数 库,⼆者要匹配,防⽌内存
泄露;
(4) 数据结构兼容:将在两种语⾔间传递的东西限制在⽤ C 编译的数据结构的范 围内;这些结构的 C++版
本可以包含⾮虚成员函数,不能有虚函数。
(5)因为C++是C的超集,且C是结构化编程语⾔,⽽C++⽀持⾯向对象编程语⾔,所以在混合编程时,
不应当出现class等⾯向对象的关键字;
主题三:类型体操(类型转换与继承)
类型转换
implicit conversion
类似于int值赋给double时,编译器会自动帮你转换对应的类型
explicit conversion
当我们在变量前加上 (type) 或者使用下文的 cast 时,我们就主动施加了强制转换。
cast(其实是显式转换的一种)
一般使用四种cast方式,
static_cast可以完成类似于c中的强制转换,
static_cast 可以在指向相关类的指针之间执行转换,不仅可以执行上行转换(从指针到派生到指针到基),还可以执行下转换(从指针到基到指针到派生)。在运行时不执行任何检查来保证正在转换的对象实际上是目标类型的完整对象。因此,由程序员来确保转换是安全的。另一方面,它不会产生 的 dynamic_cast 类型安全检查的开销。
Additionally, static_cast can also perform the following:
此外, static_cast 还可以执行以下操作:
- Explicitly call a single-argument constructor or a conversion operator.
显式调用单参数构造函数或转换运算符。 - Convert to rvalue references.
转换为右值引用。 - Convert
enum classvalues into integers or floating-point values.
将值转换为enum class整数或浮点值。 - Convert any type to
void, evaluating and discarding the value.
将任意类型转换为void,计算并放弃该值。
- 用于类层次结构中基类和派生类之间引用或指针的转换。
进行上行转换(把派生类的指针或引用转换成基类表示)是安全的。
进行下行转换(把基类的指针或引用转换成派生类表示),由于没有动态类型检查,不安全。 - 用于基本数据类型之间的转换
- 把空指针转换成目标类型的空指针
- 把任何类型的表达式转换成void类型
dynamic_cast(主要就是父类转为子类带检查)
dynamic_cast can only be used with pointers and references to classes (or with void*). Its purpose is to ensure that the result of the type conversion points to a valid complete object of the destination pointer type.
This naturally includes pointer upcast (converting from pointer-to-derived to pointer-to-base), in the same way as allowed as an implicit conversion.
But dynamic_cast can also downcast (convert from pointer-to-base to pointer-to-derived) polymorphic classes (those with virtual members) if -and only if- the pointed object is a valid complete object of the target type. 适用于多态类的上转和下转
注:Compatibility note: This type of dynamic_cast requires Run-Time Type Information (RTTI) to keep track of dynamic types. Some compilers support this feature as an option which is disabled by default. This needs to be enabled for runtime type checking using dynamic_cast to work properly with these types.
兼容性说明:此类型 dynamic_cast 需要运行时类型信息 (RTTI) 来跟踪动态类型。某些编译器支持此功能作为默认禁用的选项。需要启用此功能才能用于运行时类型检查 dynamic_cast ,以便正确处理这些类型。当转换不成立时会返回NULL,如果是指针则返回null_ptr,引用则会报告bad_alloc错误
const_cast则是用于去除常量或者voliate修饰符等的cast方式,可以把常量调整为可修改的类型
reinterpret_cast<>()则是可以对于一段内存区域进行不同的解释的方法,它保持位的二进制序列不变,只是以新的类型解释变量。这是一种非常危险的转换,它允许几乎任意类型之间的强制转换,甚至可以将指针转换为整数,或者将整数转换为指针。它不会执行任何类型检查或安全保证,适用于底层操作和低级别编程。——from xjy结构化编程 | Co-rricula
基本类型推导
auto
可以使用 auto 关键字来避免冗余的类型定义。但一定要时刻检测推导出的类型,防止出现隐式转换。
decltype
decltype (实体或表达式),推导出一个与括号中实体相同的类型,并将该类型作用于后面的对象。例如
int i = 33;
decltype(i) j = i * 2; //Type of j is int主题四:作用域与生命周期(namespace and static)
// in namespace or global scope
int i; // extern by default
const int ci; // static by default
extern const int eci; // explicitly extern
static int si; // explicitly static
// same goes for functions (but there are no global const functions)
int foo(); // extern by default
static int bar(); // explicitly staticnamespace
在约束作用域方面,替代static
有两种使用方式
declaration
using L::k; using L::f;
directive
using namespace L;
别名方式: namespace a = c;
static
The static keyword can be used to declare variables and functions at –
- global scope — variables and functions
- namespace scope — variables and functions
- class scope — variables and functions
- local scope — variables
static 关键字可以用于函数和变量,它的作用是限制函数和变量的作用域,使得它们只能在当前文件中使用。对于当前文件,static 关键字作用的变量还会将作用域扩大到全局,相当于在 main 函数外定义。
在函数内部使用 static 关键字定义的变量具有静态存储持续时间。这意味着变量在函数的多次调用之间保持其值,而不是每次调用时重新初始化。
static 初始化的原理
例1:
int main()
{
for(int x = 5; x < 10; x++)
{
static int y = x; //第一次被引用时初始化,并且只初始化一次
cout << "x = " << x << ", y = " << y << endl;
}
return 0;
}
输出结果:
x = 5, y = 5
x = 6, y = 5
x = 7, y = 5
x = 8, y = 5
x = 9, y = 5
但实际上存在一些情况
例2:
int main()
{
for(int x = 5; x < 10; x++)
{
static int y = x;
cout << "x = " << x << ", y = " << y << endl;
int *p = &y;
p++;
*p = 0;
}
return 0;
}
输出结果:
x = 5, y = 5
x = 6, y = 6
x = 7, y = 7
x = 8, y = 8
x = 9, y = 9
通过两个例子的结果我们可以知道,静态变量的初始化就是通过静态变量后面的一个32位内存位来做记录,以标识这个静态变量是否已经初始化。每次运行到当前位置,会先去判断这个地址:
如果不是1,就给它赋值1,然后给变量赋值;
如果是1,直接跳过赋值代码块这样它就做到了只赋值一次的效果;
void foo() {
static int count = 0; // 只初始化一次
count++;
std::cout << count << std::endl;
}
int main() {
foo(); // 输出 1
foo(); // 输出 2
foo(); // 输出 3
return 0;
}
类作用域
在类中使用 static 关键字定义的成员变量和成员函数属于类本身,而不是类的某个对象。静态成员变量在所有对象之间共享,静态成员函数可以在没有对象实例的情况下调用。
class MyClass {
public:
static int count; // 静态成员变量
static void increment();
}extern
函数执行机制
- 建立被调用函数的栈空间
- 参数传递
- 值传递
- 引用传递
- 保存调用函数的运行状态
- 将控制转交被调函数
Function call
Base stack pointer ->ebp
Top of stack ->esp
Summary
- 压入参数
- 保存上下文
- 保存返回地址
- 保存调用者的base pointer
- 执行函数
- 设置新的base pointer
- 分配空间
- 执行任务
- 释放空间
- 恢复上下文
- 加载调用者的base pointer
- 加载返回地址
- 继续执行调用者
主题五:重要关键字集合
inline函数的优缺点和适用场景
定义:
- 实际调用的时候,把inline函数放回原来的位置,不会产生参数的传递,在汇编上也不会有其
他的冗余操作,编译系统将为inline函数创建一段代码,在调用点,以相应的代码替换
作用:
- 增加程序的可读性
- 提高程序的运行效率
- 弥补宏定义不能及进行类型检查的缺陷
- 问题:
- 增大目标代码, 调用时必须在调用该函数的每一个文本文件中定义
- 病态换页(内存抖动)
- 降低指令快取装置的命中率
建议:
- 使用频率高的小代码使用内联
- 内联函数定义放在头文件中
- 不能含有复杂的结构控制
- 递归不能做内联函数
- 限制:
- 非递归
- 由编译系统控制
- 没有函数指针(无法写泛型、framework,表达能力降低)
Inline function
用于替代C的宏函数
提高效率
实现:编译系统将为 inline 函数创建一段代码,在调用点,以相应的代码替换(inline
只是对编译器的提示,能不能真的换要看编译器)
因此,关键字 inline 必须与函数定义体放在一起才能使函数成为内联,仅将 inline 放
在函数声明前面不起任何作用。
建议:inline函数的定义放在头文件中(而非只是声明)
类中的成员默认都是内联的
限制:
递归
函数指针
常用:小型、频繁调用的函数,避免在构造和析构函数中调用
缺点:
增大object code
病态的换页
降低指令快取装置的命中率define 的定义函数的能力比 inline 强
但是define 又缺少类型检查
template (虽然define还是更强)
optional
#include <optional>
std::optional<string>
getNameByID(
const vector<std::pair<int, string>>& v,
int id)
{ for (auto e : v) {
if (e.first == id)
return e.second;
}
return std::nullopt;
}
variant
即 type-safe union。union 的问题是可能当中的内容与解释的类型是不相符的,这会导致一系列安全性问题。而 variant 可以提供更严格的类型检查,在编译时或运行中阻止不正确的访问。
std::variant<int, float, string> v;
v = "abc";
cout << v.index() << " " << std::get<string>(v) << endl; // string, OK
v = 100;
cout << v.index() << " " << std::get<0>(v) << endl; // int, OK
v = 2.3f;
cout << v.index() << " " << std::get<float>(v) << endl; // float, OK
cout << v.index() << " " << std::get<double>(v) << endl; // double, not found in type list, compile ERROR
cout << v.index() << " " << std::get<int>(v) << endl; // int, not the corresponding type, runtime exception
float* pf = std::get_if<float>(&v); // we can use guard pointer to judge.
if(pf != nullptr){ // float, OK
cout << v.index() << " " << std::get<float>(v) << endl;
}else{ // not float, invalid!
cout << "Invalid" << endl;
}any
如果不能将返回值显式地表现出来,可以直接用 any 来进行封装。any 相当于是一个篮子,它可以接受任何类型的返回值。它相当于是更安全的 void*
any input(){
int i;
cin >> i;
switch(i){
case 0:
return 11;
break;
case 1:
return 3.14;
break;
default:
return string("Hello, world!");
break;
}
}
int main(){
any aa;
aa = input();
if(aa.type() == typeid(int)){//using typeid to judge its type
// do something...
}else if(aa.type() == typeid(double)){
// do something...
}else{
// do something...
}
}const
1.正常const常量定义:
const int a = 10;2.含const的指针
const double pi = 3.1415;
const double *cptr = & pi;
*cptr = 42; //错误:常量指针不能修改对应的值
const double *coll;
const double c = 0.0;
coll = &c;
cptr = coll;//允许更换指针
const double pi = 3.14;
const double *const pip = π //从右向左依次解修饰符,首先pip是一个常量,然后是*说明pip是一个常量指针,
//再然后是double说明是指向double的指针,最后是const说明这个double不能变,即指向的对象是一个常量的doublefinal
当用于类时,final 关键字表明这个类不能被继承。这意味着没有任何其他类可以继承
这个被标记为final 的类。
当用于成员函数时,final 关键字表明这个成员函数不能被任何派生类重写。也就是说,这个函数的实现是最终的,不允许在派生类中被覆盖
final 关键字可以与virtual 关键字一起使用,以阻止派生类重写特定的虚函数
#include <iostream>
class Base {
public:
virtual void print() final { // 标记为 final,禁止重写
std::cout << "Base::print\n";
}
};
class Derived : public Base {
public:
// 错误:不能重写 final 函数
void print() override {
std::cout << "Derived::print\n";
}
};
int main() {
Derived obj;
obj.print();
return 0;
}override

纯虚函数:纯虚函数是声明时在函数原型后加上=0 (往往只声明,不实现)
纯虚函数:只有函数接口会被继承
只有函数接口会被继承
子类必须继承函数接口,必须提供实现代码
一般虚函数:函数的接口及缺省实现代码都会被继承
子类必须继承函数接口
可以继承缺省实现代码
非虚函数:函数的接口和其实现代码都会被继承
会同时继承接口和实现代码
class Base {
public:
void print() { // 非虚函数
std::cout << "Base::print\n";
}
};
class Derived : public Base {
public:
void print() { // 隐藏基类的非虚函数
std::cout << "Derived::print\n";
}
};
int main() {
Base* obj = new Derived();
obj->print(); // 调用 Base::print(静态绑定)
delete obj;
return 0;
}| 特性 | 纯虚函数 | 一般虚函数 | 非虚函数 |
|---|---|---|---|
| 定义 | virtual void func() = 0; | virtual void func(); | void func(); |
| 接口继承 | 是 | 是 | 是 |
| 实现继承 | 否 | 是(默认实现) | 是 |
| 子类必须实现 | 是 | 否(可重写) | 否(不能重写) |
| 多态性 | 是(动态绑定) | 是(动态绑定) | 否(静态绑定) |
| 用途 | 定义接口 | 提供默认行为,允许重写 | 实现不需要多态的行为 |
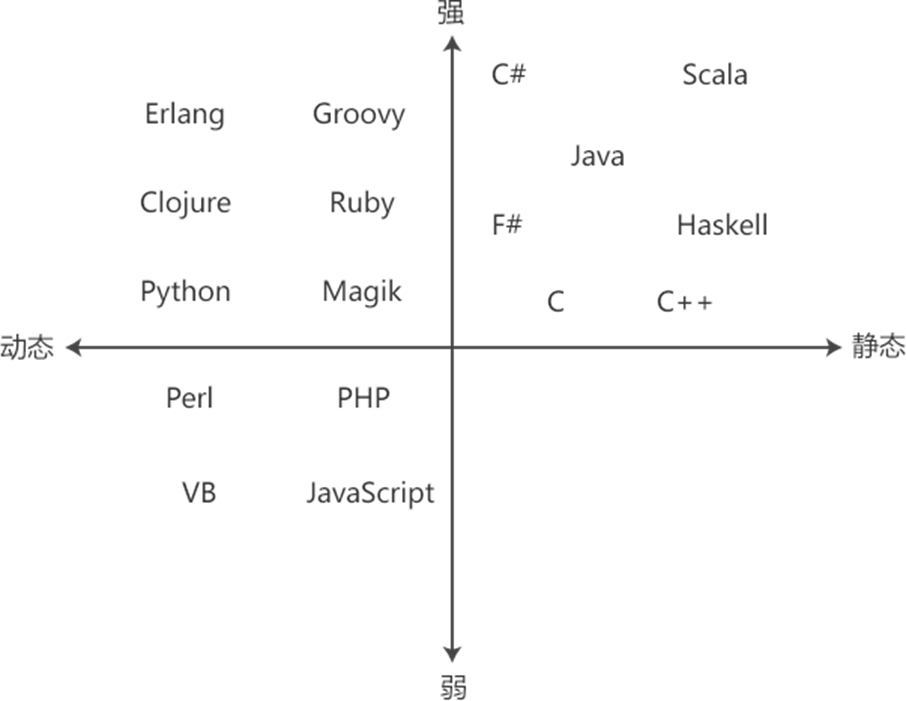
多继承
如果直接基类有公共的基类,则该公共基类中的成员变量在多继承的派生类中有多个副本
C如何解决名冲突问题?
设计理念: (Base-Class Decomposition)将共同的属性抽象出一个父类
实现机制: 虚继承
class A;
class B: virtual public A;
class C: virtual public A;
class D: B,C最新的派生类(即多重继承链中最后的类)负责构造虚基类
虚基类的构造函数优先非虚基类的构造函数执行(先调A再调BC最后是D本身)
#include <iostream>
class Base {
public:
Base(int value) {
std::cout << "Base constructor, value: " << value << "\n";
}
};
class Derived1 : virtual public Base {
public:
Derived1(int value) : Base(value) {
std::cout << "Derived1 constructor\n";
}
};
class Derived2 : virtual public Base {
public:
Derived2(int value) : Base(value) {
std::cout << "Derived2 constructor\n";
}
};
class Final : public Derived1, public Derived2 {
public:
// 最派生类直接调用虚基类的构造函数
Final(int value1, int value2) : Base(value1), Derived1(value1), Derived2(value2) {
std::cout << "Final constructor\n";
}
};
int main() {
Final obj(10, 20);
return 0;
}赋值操作符重载不能继承
- 每一个类对象实例在创建的时候,如果用户没有定义“赋值运算符重载函数”,那么,编
译器会自动生成一个隐含和默认的“赋值运算符重载函数” (即默认拷贝赋值函数) - 如果派生类中声明的成员与基类的成员同名,那么,基类的成员会被覆盖,哪怕基类的
成员与派生类的成员的数据类型和参数个数都完全不同,所以派生类的拷贝赋值函数覆
盖了基类的赋值操作符重载
主题六:模板元编程与非OOP的多态

在编译期这个代码就可以使用模板实例化展开计算得到对应结果
constexpr
constexpr 是 C++11 引入的一个关键字,用于指示表达式或函数在编译时求值。它允许编译器在编译时计算常量值,从而提高程序的性能和安全性。以下是 constexpr 的主要特点和在模板元编程中的作用:
constexpr 的主要特点
- 编译时求值:
constexpr函数和变量在编译时求值,减少了运行时的计算开销。 - 常量表达式:
constexpr函数可以返回常量表达式,允许在编译时进行更复杂的计算。 - 类型安全:
constexpr提供了类型安全的编译时计算,避免了宏定义带来的潜在问题。
constexpr 在模板元编程中的作用
- 编译时计算:在模板元编程中,
constexpr可以用于编译时计算常量值,从而生成更高效的代码。例如,可以使用constexpr函数计算数组的大小或初始化常量数组。 - 类型特征检测:
constexpr可以用于编写类型特征检测函数,在编译时确定类型的特性。例如,可以使用constexpr函数检测类型是否具有特定的成员函数或类型定义。 - 递归计算:
constexpr函数支持递归调用,可以在编译时进行复杂的递归计算。例如,可以使用constexpr函数计算斐波那契数列或阶乘。 - 编译时断言:
constexpr可以用于编写编译时断言,确保模板参数满足某些条件。例如,可以使用constexpr函数在编译时检查模板参数的范围或类型。
函数模板
C中模板的完整定义通常出现在头文件
主题七:纯血OOP
#include <stdio.h>
#include <stdlib.h>
template<typename T>
struct Stack {
T* array;
int capacity;
int top;
void _init(int capacity) {
array = (T*)malloc(sizeof(T) * capacity);
this->capacity = capacity;
this->top = -1;
}
void _push(T data) {
if (top + 1 >= capacity) {
printf("Stack is full\n");
return;
}
array[++top] = data;
}
T _pop() {
if (top < 0) {
printf("Stack is empty\n");
return 0;
}
return array[top--];
}
void _release() {
free(array);
capacity = 0;
top = -1;
}
};#include <iostream>
using namespace std;
template<typename T>
class Stack {
private:
T* array;
int capacity;
int top;
public:
Stack(int capacity) {
array = new T[capacity];
this->capacity = capacity;
this->top = -1;
}
void _push(T data) {
if (top + 1 >= capacity) {
printf("Stack is full\n");
return;
}
array[++top] = data;
}
T _pop() {
if (top < 0) {
printf("Stack is empty\n");
return 0;
}
return array[top--];
}
~Stack() {
delete[] array;
capacity = 0;
top = -1;
}
};请注意比较两者的差异
类的继承
基于目标代码的复用
对事物进行分类
增量开发
继承是有权限控制的(不写是默认private的,基类中的任何元素都访问不到)
class Student{ };
class Undergraduate_Student : public Student{ };
注意友元是不被继承的

编译器会把ptr作为B类使用(除非使用dynamic_cast)
派生类的友元函数不能访问基类的protected成员(派生类可以访问),private当然更不行了
派生类对象初始化
基类和派生类共同完成
构造函数的执行次序
基类的构造函数
派生类对象成员类的构造函数
派生类的构造函数
缺省执行基类默认构造函数
要执行基类非默认构造函数,必须在派生类构造函数的初始化列表中指出
#include <iostream>
class Base {
public:
Base(int value) {
std::cout << "Base构造函数,value: " << value << "\n";
}
};
class Derived : public Base {
public:
// 在初始化列表中显式调用基类的非默认构造函数
Derived(int value) : Base(value) {
std::cout << "Derived构造函数\n";
}
};
int main() {
Derived obj(10); // 创建派生类对象
return 0;
}#include <iostream>
class Base {
public:
Base(int value) {
std::cout << "Base构造函数,value: " << value << "\n";
}
};
class Derived : public Base {
public:
Derived() { // 错误:没有显式调用基类的构造函数
std::cout << "Derived构造函数\n";
}
};
int main() {
Derived obj; // 编译错误
return 0;
}修复
class Derived : public Base {
public:
Derived() : Base(0) { // 显式调用基类的构造函数
std::cout << "Derived构造函数\n";
}
};虚函数
类型相容->赋值相容
类型相容x<-赋值相容
class A{};
class B: public A{};
A a; B b;
a=b;a=b实际调用了一个拷贝函数
对象的身份发生变化,属于派生类的属性不再存在(对象切片——对象身份发生了变化)
使用多态写程序时,要避免将栈上的对象赋值给另一个对象
虚函数的来历
C中的对象都是前期绑定的
- 编译时
- 依据对象静态类型
- 效率高、灵活性差
- 难以实现多态 动态绑定
- 但又要注重效率
- 默认前期绑定
- 动态绑定需显式指出(virtual)
为类的成员方法声明virtual
根据实际引用和指向的对象类型动态绑定
如在基类中被定义为虚成员函数,则派生类中对其重定义的成员函数均为虚函数
#include <iostream>
class Base {
public:
virtual void print() { // 声明虚函数
std::cout << "Base::print\n";
}
};
class Derived : public Base {
public:
void print() override { // 重写虚函数
std::cout << "Derived::print\n";
}
};
int main() {
Base* obj = new Derived(); // 基类指针指向派生类对象
obj->print(); // 调用 Derived::print
delete obj;
return 0;
}limit:
- 只有类的成员函数才可以是
- 静态函数、内联函数不能
- 构造函数不能是虚函数
- 在构造函数完成之前,无法找到作为虚函数的构造函数所在的代码区,所以构造函数只能作为
- 普通函数存放在类所指定的代码区中
- 析构函数可以是虚函数(往往是)
- 如果析构函数不是虚函数,那么调用的将会是基类的析构函数。我们更希望可以调用派生类的
- 析构函数对新定义的成员也进行析构
需要额外的内存空间存储对象可以调用的相应虚函数
对象的内存空间中含有指针,指向其虚函数表
每个对象有多少虚函数是不确定的
编译时获得虚函数表,这样就知道如何确定应调用的函数
实例化一个类的对象的时候, 会使用一个指针记录这个类的虚函数表的首地址
一些重要例子:(必须掌握)


- 此时的A f是A的构造函数中调用的,此时还没进行B的构造,所以即使f是虚函数,也
不会调用B中的 (直到构造函数返回后,对象方可正常使用) - f是虚函数,调用B的
- g不是虚函数,调用基类的
- h不是虚函数,调用基类中的,接着根据虚函数表去调用f,由于此时环境中的this是在
A中的,调用A的g
tip:
避免在构造函数中调用虚函数(直到构造函数返回后,对象方可正常使用)
进入虚函数后,都是根据当前类型确定(切换了上下文)
不要定义与继承来的非虚函数同名的成员函数
绝对不要重新定义继承来的缺省参数值(静态绑定,如果使用的是父类的指针指向子类,子类
覆盖的缺省参数值是无效的)
主题八:重载函数总结
双目操作符重载:<refType> operator #(args)
隐含this
a#b 实际表现为
a.operator#(b)
Complex {};
Complex operator+(Complex& x1,Complex& x2){ }
c=a+boperator<<只能作为全局函数重载
ostream& operator<<(ostream& o,Day d){ }= () [] ->不能作为全局函数重载
不可被重载的操作符: . .* :: ?:
永远不要重载 &&和 | | =>破坏了短路机制

#include <functional>
#include <iostream>
#include <limits>
#include <string>
#include <unordered_map>
class IntStream {
public:
explicit IntStream(int first) : first_(first), current_(first), last_(std::numeric_limits<int>::max()), stride_(1) {}
IntStream(int first, int last) : first_(first), current_(first), last_(last), stride_(1) {}
IntStream(int first, int last, int stride) : first_(first), current_(first), last_(last), stride_(stride) {}
IntStream &operator++() {
if (!finished()) {
current_ += stride_;
}
return *this;
}
IntStream operator++(int) {
IntStream temp = *this;
++(*this);
return temp;
}
int operator*() const {
return current_;
}
operator bool() const {
return !finished();
}
private:
bool finished() const {
if (stride_ > 0) {
return current_ >= last_;
} else if (stride_ < 0) {
return current_ <= last_;
} else {
return false; // Infinite loop if stride is 0
}
}
int first_;
int current_;
int last_;
int stride_;
};
void print_answer(const IntStream &s, int expect) {
std::cout << std::boolalpha;
if (s) {
std::cout << (*s == expect) << ' ' << *s << std::endl;
} else {
std::cout << false << std::endl;
}
}
/**
* @brief 测试 IntStream(int)
*/
void test_1() {
IntStream s(0);
for (size_t i = 0; i < 10; i++) {
++s;
}
print_answer(s, 10);
}
/**
* @brief 测试范围 [first, last) 非常大的情况
*/
void test_8() {
IntStream s(std::numeric_limits<int>::min(), std::numeric_limits<int>::max());
for (size_t i = 0; i < 10000; i++) {
s++;
}
print_answer(s, std::numeric_limits<int>::min() + 10000);
}
int main() {
std::unordered_map<std::string, std::function<void()>> test_cases_by_name = {
{"test_1", test_1}, {"test_2", test_2}, {"test_3", test_3},
{"test_4", test_4}, {"test_5", test_5}, {"test_6", test_6},
{"test_7", test_7}, {"test_8", test_8},
};
std::string tname;
std::cin >> tname;
auto it = test_cases_by_name.find(tname);
if (it == test_cases_by_name.end()) {
std::cout << "输入只能是 test_<N>,其中 <N> 可取整数 1 到 8." << std::endl;
return 1;
}
(it->second)();
}#include <iostream>
using namespace std;
class temp{
int a;
int b;
public:
temp(){
a = 1;
b = 2;
}
friend ostream& operator<<(ostream& os, const temp& t);
};
ostream& operator<<(ostream& os, const temp& t){
os<<t.a<<" "<<t.b;
return os;
}
int main(){
temp t;
cout<<t<<endl;
return 0;
}
=重载(需要避免自赋值)
Base& operator=(const Base& other) {
if (this != &other) {
value = other.value;
}
return *this;
} class A{
int x,y;
char *p;
A& operator=(A& a){
if(this &rhs) return *this
}
}下标操作
class string{
char *p;
public:
string(char *p1){
p = new char[strlen(p1)+1];
strcpy(p,p1);
}
char &operator [](int i) const { return p[i]; }
const char operator [](int i) const { return p[i]; }
}为了避免对下标操作符取的值修改,再次重载
为什么返回值不同的函数能重载成功? 加上const后,this的类型不同,非常量的版本和常
量版本调用的不同
对于下标操作符的重载,要重载常量和非常量两个版本
括号操作符
仿函数使用
策略模式
代理/智能指针
减少混合计算中需要定义的操作符重载函数的数量
#include <iostream>
class Multiplier {
private:
int factor;
public:
Multiplier(int f) : factor(f) {}
// 重载括号操作符
int operator()(int x) {
return x * factor;
}
};
int main() {
Multiplier multiplyBy2(2); // 创建仿函数对象,factor = 2
Multiplier multiplyBy3(3); // 创建仿函数对象,factor = 3
std::cout << "2 * 5 = " << multiplyBy2(5) << "\n"; // 输出:10
std::cout << "3 * 5 = " << multiplyBy3(5) << "\n"; // 输出:15
return 0;
}->操作符
是二元运算符,重载时按一元操作符描述 返回指针类型或者自定义操作符的类型
#include <iostream>
class MyClass {
public:
void print() {
std::cout << "Hello, World!\n";
}
};
class Wrapper {
private:
MyClass* ptr;
public:
Wrapper(MyClass* p) : ptr(p) {}
// 重载 -> 操作符
MyClass* operator->() {
return ptr;
}
};
int main() {
MyClass obj;
Wrapper wrapper(&obj);
wrapper->print(); // 通过重载的 -> 操作符访问成员函数
return 0;
}还有new和delete的重载见上文(第一章)
主题九:异常处理
异常——Exception
- 运行环境造成
- 内存不足,文件操作失败
- 异常处理
- 当发生异常,程序无法沿着正常的顺序执行下去的时候,立即结束程序可能并不妥
当。我们需要给程序提供另外一条可以安全退出的路径
特征:可以预见,无法避免
异常处理机制
try 监控
throw 抛掷异常对象
throw 抛出异常时,将暂停当前函数的执行,开始查找匹配的catch子句。沿着函数的嵌套调用链向 上查找,直到找到一个匹配的catch子句,或者找不到匹配的catch子句(调用abort终 止)。
无参数throw
将捕获到的异常对象重新抛出
析构函数不应抛出异常(noexcept)
如果析构函数中出现异常,那么就应该在析构函数内部将这个异常进行处理,而不是将异常抛出去。
为什么不应该?抛出异常的就是栈展开的过程,而栈展开会调用析构函数销毁局部对象,这样多次调用析构函数会导致程序崩溃(内存泄漏)
构造函数可以抛出异常
当构造函数内出现异常,可以选择将异常抛出,在栈展开的过程调用析构函数释放已申请的内
存,也可以在内部将异常处理,手动调用delete释放
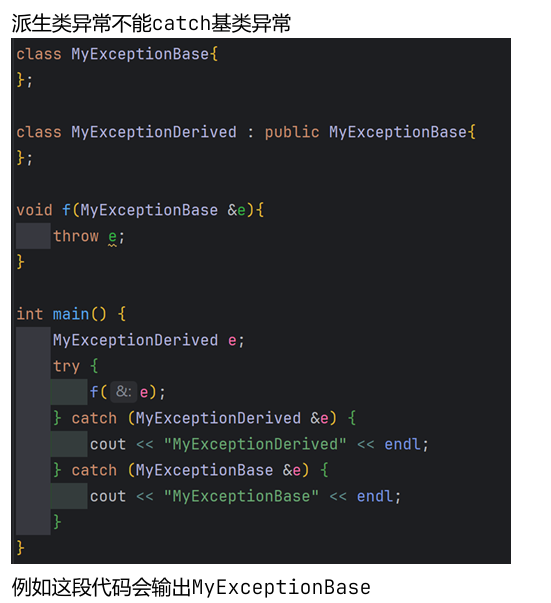
catch
catch( var ) {<语句序列>}
类型:异常类型,匹配规则同函数重载 catch的异常类型是严格匹配的
变量:存储异常对象,可省略 try后可以跟多个catch语句块
主题十:一些初始化
函数参数列表初始化
形似这样:
int function(int a, int b = 10, int c = 11); // 正确默认参数必须从右到左依次设置。也就是说,如果一个参数有默认值,那么它右边的所有参数也必须具有默认值。
int function(int a = 1, int b, int c = 11); // 错误:b 没有默认值
int function(int a = 1, int b = 10, int c); // 错误:c 没有默认值
int result1 = function(1); // a=1, b=10, c=11
int result2 = function(1, 20); // a=1, b=20, c=11
int result3 = function(1, 20, 30); // a=1, b=20, c=30这样的调用方式是正确的
