

操作系统
Contents
- 1 Intro
- 2 Part I Virtualization
- 2.1 The Abstraction: The Process
- 2.2 Process API
- 2.3 Process Creation: A Little More Detail
- 2.4 Process States
- 2.5 Data Structure
- 2.6 Process API
- 2.7 Mechanism: Limited Direct Execution(受限直接执行)
- 2.8 CPU-Scheduling
- 2.9 new metric: response time
- 2.10 Incorporating I/O
- 2.11 Scheduling: The Multi-Level Feedback Queue
- 2.12 Scheduling: Proportional Share
- 3 关于CPU虚拟化的总结
- 4 The Abstraction: Address Spaces(抽象:地址空间)
- 5 Part II 并发
Intro
They are the three key ideas we’re going to learn about: virtualiza
I hear and I forget. I see and I remember. I do and I
tion, concurrency, and persistence.
understand.
Part I Virtualization
The Abstraction: The Process
one of THE MOST FUNDAMENTAL ABSTRACTIONS—— the process
THE CRUX OF THE PROBLEM:
HOWT O PROVIDE THE ILLUSION OF MANY CPUS?
Although there are only a few physical CPUs available, how can the
OSprovide the illusion of a nearly-endless supply of said CPUs?
the OS creates this illusion by virtulizing the CPU.
To implement virtualization of the CPU, and to implement it well, the
OS will need both some low-level machinery and some high-level in
telligence. We call the low-level machinery mechanisms(机器机制);
For example, context switch(上下文切换)
TIP: USE TIME SHARING (AND SPACE SHARING)
Time sharing is a basic technique used by an OS to share a resource. By allowing the resource to be used for a little while by one entity, and then a little while by another, and so forth, the resource in question (e.g., the CPU, or a network link) can be shared by many. The counterpart of time sharing is space sharing, where a resource is divided (in space) among those who wish to use it. For example, disk space is naturally a space shared resource; once a block is assigned to a file, it is normally not as signed to another file until the user deletes the original file.
A
scheduling policy in the OS will make this decision, likely using historical information (e.g., which program has run more over the last minute?), workload knowledge (e.g., what types of programs are run), and performance metrics (e.g., is the system optimizing for interactive performance, or throughput?) to make its decision.即使用一些信息进行时间分配
The abstraction provided by the OS of a running program is something we will call a process.
to understand a process, we need to understand the machine state
分离策略和机制:在许多操作系统中,一个通用的设计范式是将高级策略与其低级机制分开。可以将【机制】看成 为系统的“how”问题提供答案。例如操作系统如何进行上下文切换?【策略】为“which”问题提供答案。例如操作系统该运行哪个进程?将两者分开可以轻松的改变策略,而不必重新考虑机制,因此,这是一种模块化的形式,一种通用软件的设计原则。
Process API
- Create:(创建) An operating system must include some method to cre
ate new processes. When you type a command into the shell, or
double-click on an application icon, the OS is invoked to create a
newprocess to run the program you have indicated. - Destroy:(销毁) As there is an interface for process creation, systems also
provideaninterfacetodestroyprocessesforcefully. Ofcourse, many
processes will runandjustexitbythemselveswhencomplete; when
they don’t, however, the user may wish to kill them, and thus an in
terface to halt a runaway process is quite useful. - Wait: Sometimes it is useful to wait for a process to stop running;
thus some kind of waiting interface is often provided. - Miscellaneous Control:(其他控制) Other than killing or waiting for a process,
there are sometimes other controls that are possible. For example,
most operating systems provide some kind of method to suspend a
process (stop it from running for a while) and then resume it (con
tinue it running).比如暂停一些进程然后过一会恢复 - Status:(状态) There are usually interfaces to get some status information
about a process as well, such as how long it has run for, or what
state it is in.用于获取一些进程状态信息
©2008–23, ARPACI-DUS
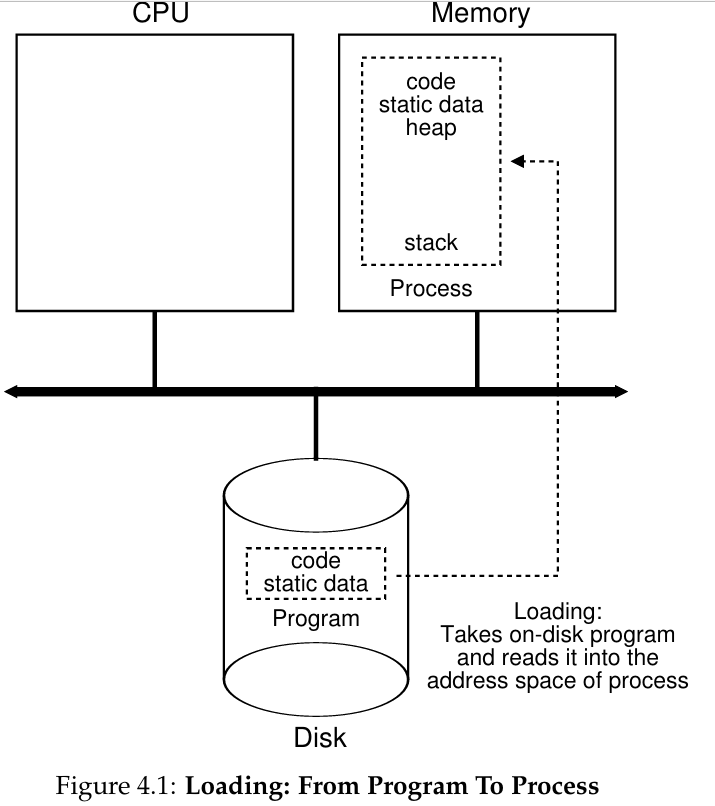
Process Creation: A Little More Detail
The first thing that the OS must do to run a programis to load its code and any static data (e.g., initialized variables) into memory, into the address space of the process. Programs initially reside on disk (or, in some modern systems, flash-based SSDs) in some kind of executable format; thus, the process of loading a program and static data into memory requires the OS to read those bytes from disk and place them in memory somewhere.描述了基本的加载流程,即从disk中读取程序信息到memory中
In early OS, the loading process is done eagerly, but was lazier done in modern OSes. This relates to the machinery of paging and swapping.
Once the code and static data are loaded into memory, there are a fewother things the OS needs to do before running the process. Some memory must be allocated for the program’s run-time stack (or just stack).As you should likely already know, C programs use the stack for local variables, function parameters, and return addresses; the OS allocates this memory and gives it to the process. The OS will also likely initialize the stack with arguments; specifically, it will fill in the parameters to the main() function, i.e., argc and the argv array.(加载过后实行栈机制)The OS mayalso allocate some memory for the program’s heap. (堆中的空间通常使用比如malloc这样的C语言函数调取free()释放)
Process States
- Running: In the running state, a process is running on a processor.
This means it is executing instructions. - Ready: In the ready state, a process is ready to run but for some
reason the OS has chosen not to run it at this given moment. - Blocked: In the blocked state, a process has performed some kind
of operation that makes it not ready to run until some other event
takes place. A common example: when a process initiates an I/O
request to a disk, it becomes blocked and thus some other process
can use the processor.
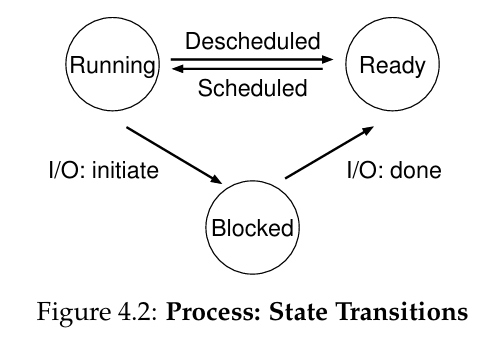
As you can see in the diagram, a process can be moved between the ready and running states at the discretion of the OS. Being moved from ready to running means the process has been scheduled; being moved from running to ready means the process has been descheduled. Once a process has become blocked (e.g., by initiating an I/O operation), the OS will keep it as such until some event occurs (e.g., I/O completion)


Data Structure
ASIDE: DATA STRUCTURE — THE PROCESS LIST Operating systems are replete with various important data structures that we will discuss in these notes. The process list (also called the task list) is the first such structure. It is one of the simpler ones, but certainly any OS that has the ability to run multiple programs at once will have something akin to this structure in order to keep track of all the running programs in the system. Sometimes people refer to the individual structure that stores information about a process as a Process Control Block (PCB), a fancy way of talking about a C structure that contains information about each process (also sometimes called a process descriptor).
Process API
Fork()
系统调用fork()用于创建新进程[C63]。但要小心,这可能是你使用过的最奇怪的接口



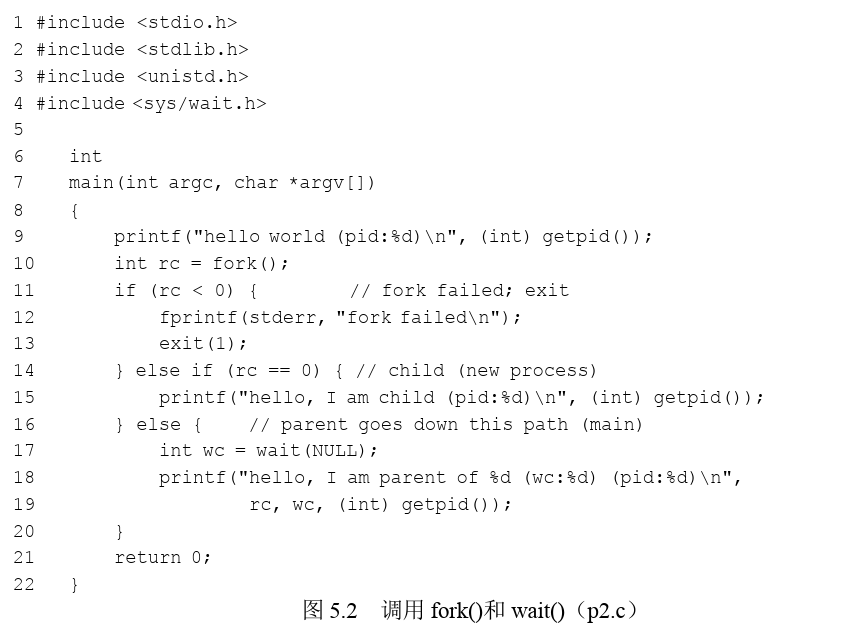

fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
- 在父进程中,fork返回新创建子进程的进程ID;
- 在子进程中,fork返回0;
- 如果出现错误,fork返回一个负值;
Wait()
到目前为止,我们没有做太多事情:只是创建了一个子进程,打印了一些信息并退出。事实表明,有谁谁父进程需要等待子进程执行完毕,这很有用。这项任务由wait()系统调用(或者更完整的兄弟接口waitpid())
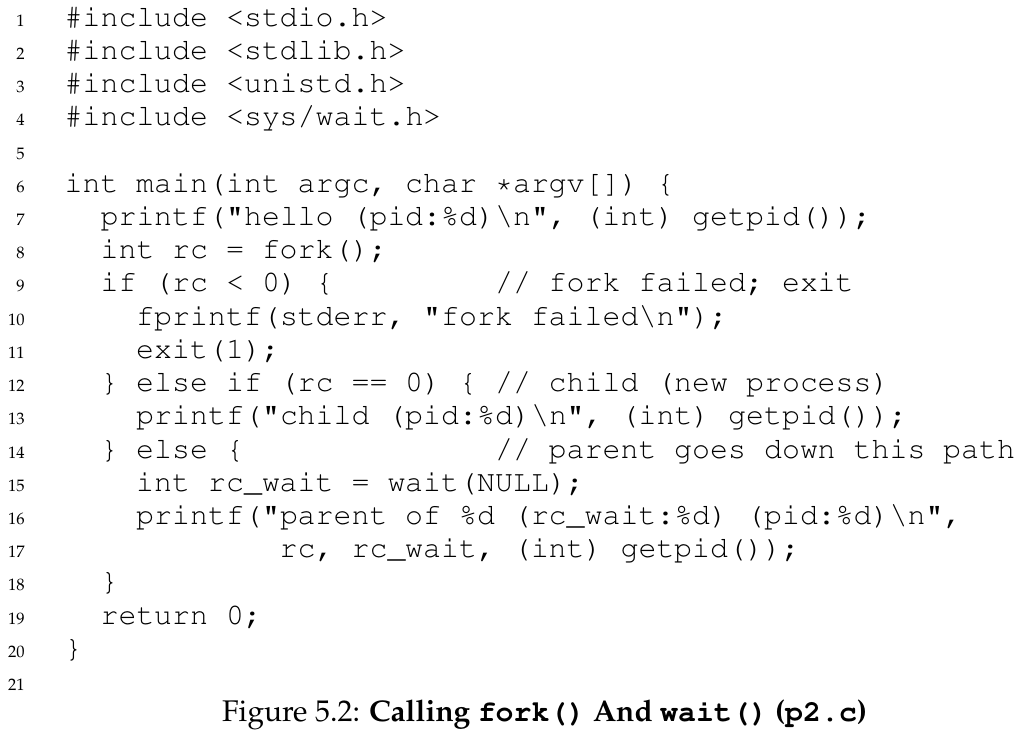
The CPU scheduler, a topic we’ll discuss in great detail soon, determines which process runs at a given moment in time; because the scheduler is complex, we cannot usually make strong assumptions about what it will choose to do, and hence which process will run first. This nondeterminism, as it turns out, leads to some interesting problems, particularly in multi-threaded programs; hence, we’ll see a lot more nondeterminism when we study concurrency in the second part of the book.

exec()
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 #include <string.h>
5 #include <sys/wait.h>
6
7 int
8 main(int argc, char *argv[])
9 {
10 printf("hello world (pid:%d)\n", (int) getpid());
11 int rc = fork();
12 if (rc < 0) { // fork failed; exit
13 fprintf(stderr, "fork failed\n");
14 exit(1);
15 } else if (rc == 0) { // child (new process)
16 printf("hello, I am child (pid:%d)\n", (int) getpid());
17 char *myargs[3];
18 myargs[0] = strdup("wc"); // program: "wc" (word count)
19 myargs[1] = strdup("p3.c"); // argument: file to count
20 myargs[2] = NULL;
// marks end of array
21 execvp(myargs[0], myargs); // runs word count
22 printf("this shouldn't print out");
23 } else { // parent goes down this path (main)
24 int wc = wait(NULL);
25 printf("hello, I am parent of %d (wc:%d) (pid:%d)\n",
26 rc, wc, (int) getpid());
27 }
28 return 0;
29 } 这样设计API的理由:分离fork()和exec()的做法能够在运行新程序之前改变fork出来的环境之后再exec,可以更容易实现一些有趣的功能
Mechanism: Limited Direct Execution(受限直接执行)
There are a few challenges, however, in building such virtualization machinery. The first is performance: how can we implement virtualization without adding excessive overhead to the system? The second is control: how can we run processes efficiently while retaining control over the CPU? Control is particularly important to the OS, as it is in charge of resources; without control, a process could simply run forever and take over the machine, or access information that it should not be allowed to access. Obtaining high performance while maintaining control is thus one of the central challenges in building an operating system.
第一个是性能:如何在不增加系统开销的情况下实现虚拟化?第二个是控制权:如何有效地运行进程
THE CRUX:
HOW TO EFFICIENTLY VIRTUALIZE THE CPU WITH CONTROL
The OS must virtualize the CPU in an efficient manner while retaining control over the system. To do so, both hardware and operating-system support will be required. The OS will often use a judicious bit of hardware support in order to accomplish its work effectively.
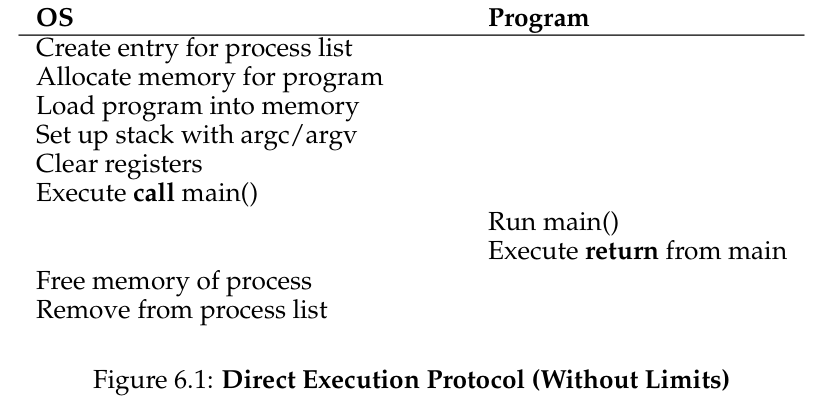
But this approach gives rise to a few problems in our quest to virtualize the CPU. The first is simple: if we just run a program, how can the OS make sure the program doesn’t do anything that we don’t want it to do, while still running it efficiently? The second: when we are running a process, how does the operating system stop it from running and switch to another process, thus implementing the time-sharing we require to virtualize the CPU?
Problem 1 _Restricted Operations(限制操作)
One approach would simply be toletany process do what ever it wants in terms of I/O and other related operations. However, doing so would prevent the construction of many kinds of systems that are desirable.
例如,如果我们希望构建一个在授予文件访问权限前检查权限的文件系统,就不能简单地让任何用户进程向磁盘发出I/O。如果这样做,一个进程就可以读取或写入整个磁盘,这样所有的保护都会失效。
Thus, the approach we take is to introduce a new processor mode, known as user mode.In this mode code is restricted when doing something.
In contrast to user mode is kernel mode.
which the operating system
(or kernel) runs in. In this mode, code that runs can do what it likes, including privileged operations such as issuing I/O requests and executing all types of restricted instructions.
要执行系统调用,程序必须执行特殊的陷阱(trap)指令。该指令同时跳入内核并将特权级别提升到内核模式。一旦进入内核,系统就可以执行任何需要的特权操作(如果允许),从而为调用进程执行所需的工作。完成后,操作系统调用一个特殊的从陷阱返回(return-from-trap)指令,如你期望的那样,该指令返回到发起调用的用户程序中,同时将特权级别降低,回到用户模式。
还有一个重要的细节没讨论:
陷阱如何知道在OS内运行哪些代码?
显然,发起调用的过程不能指定要跳转到的地址
内核通过在启动时设置陷阱表(trap table)来实现。当机器启动时,它在特权(内核)模式下执行,因此可以根据需要自由配置机器硬件。操作系统做的第一件事,就是告诉硬件在发生某些异常事件时要运行哪些代码。例如,当发生硬盘中断,发生键盘中断或程序进行系统调用时,应该运行哪些代码?操作系统通常通过某种特殊的指令,通知硬件这些陷阱处理程序的位置。一旦硬件被通知,它就会记住这些处理程序的位置,直到下一次重新启动机器,并且硬件知道在发生系统调用和其他异常事件时要做什么(即跳转到哪段代码)
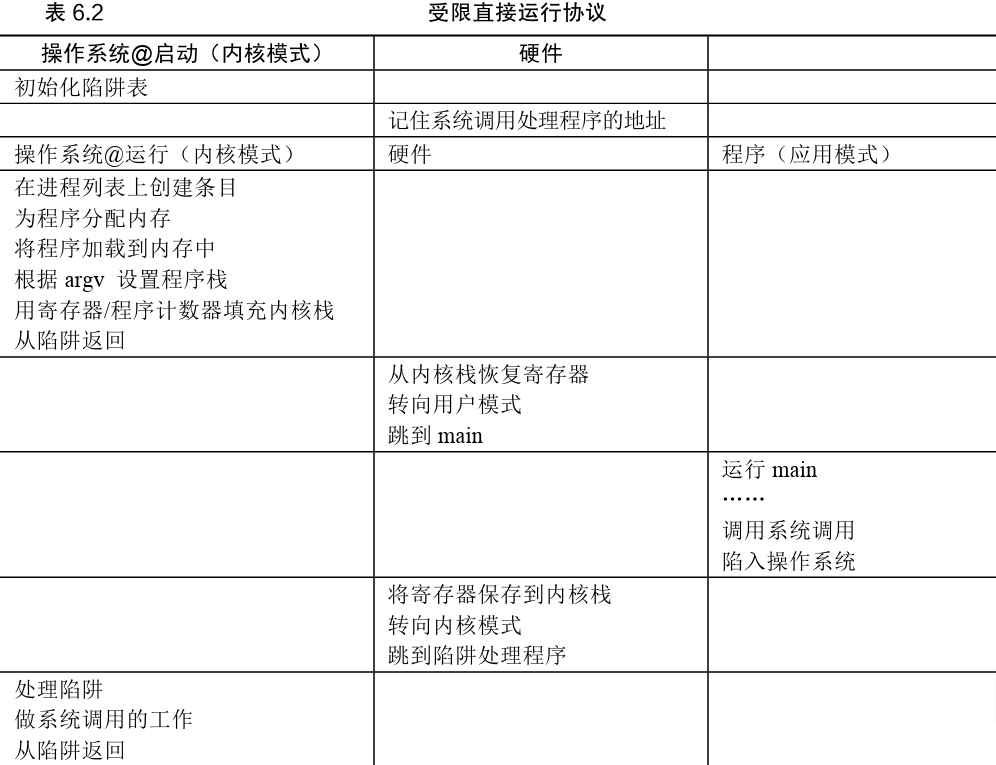

Problem #2: Switching Between Processes问题2——在进程之间切换
事实证明,没有硬件的额外帮助,如果进程拒绝进行系统调用(也不出错),从而将控制权交还给操作系统,那么操作系统无法做任何事情。
协作方式:进程放弃CPU,然后将控制权交给操作系统以便于系统运行其他进程。如果应用程序执行了某些非法操作也会把控制权转移给操作系统(trap陷入),操作系统再次控制CPU。
You might also be thinking: isn’t this passive approach less than ideal? What happens, for example, if a process (whether malicious, or just full of bugs) ends up in an infinite loop, and never makes a system
call? What can the OS do then?
关键问题:如何在没有协作的情况下获得控制权
The answer turns out to be simple and was discovered by a number of people building computer systems many years ago: a timer interrupt.
A timer device can be programmed to raise an interrupt everyso many milli-seconds; when the interrupt is raised, the currently running process is halted, and a pre-configured interrupt handler in the OS runs.
At this point, the OS has regained control of the CPU, and thus can do what it pleases: stop the current process, and start a different one.
Saving and Restoring Context
If the decision is made to switch, the OS then executes a low-level piece of code which we refer to as a context switch. A context switch is conceptually simple: all the OS has to do is save a few register values
for the currently-executing process (onto its kernel stack, for example) and restore a few for the soon-to-be-executing process (from its kernel stack).
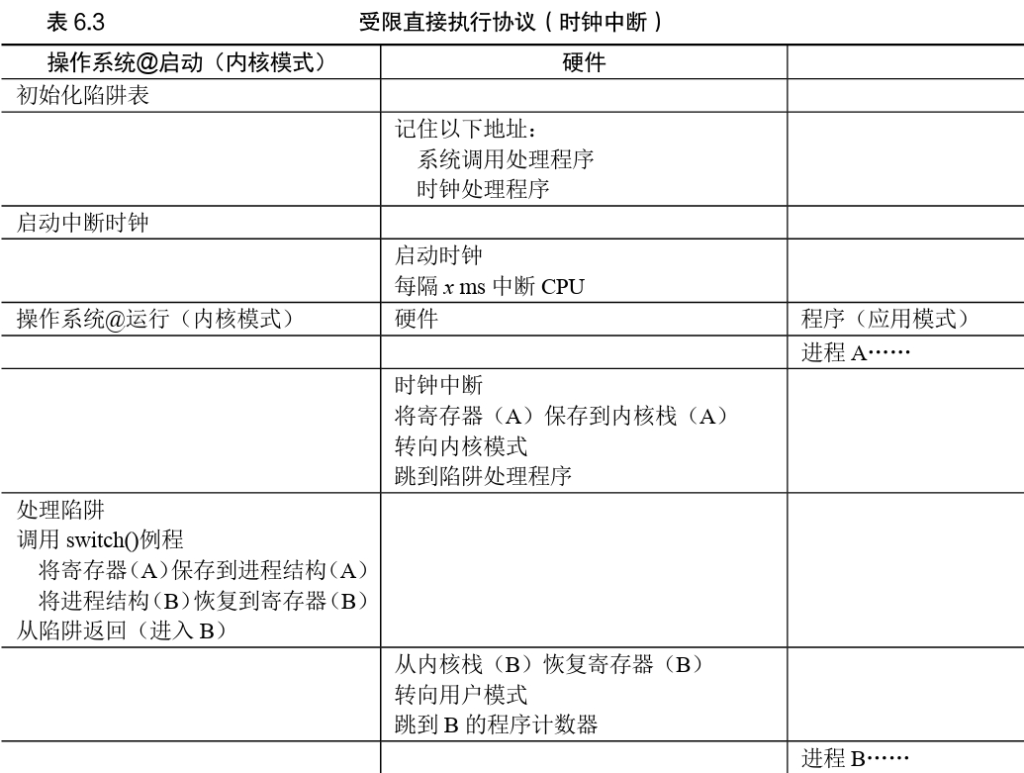
CPU-Scheduling
This part is mainly about different sheduling policy, and mainly focus on the key problem:how to develop sheduling policy?
workload assumption
探讨可能的策略范围之前,我们先做一些简化假设。这些假设与系统中运行的进程有关,有时候统称为工作负载(workload)。确定工作负载是构建调度策略的关键部分。工作负载了解得越多,你的策略就越优化。
我们对操作系统中运行的进程(有时也叫工作任务)做出如下的假设:
1.每一个工作运行相同的时间。
2.所有的工作同时到达。
3.一旦开始,每个工作保持运行直到完成。
4.所有的工作只是用 CPU(即它们不执行 IO 操作)。
5.每个工作的运行时间是已知的。
Scheduling metrics(调度指标)
For now, however, let us also simplify our life by simply having a single metric: turnaround time.
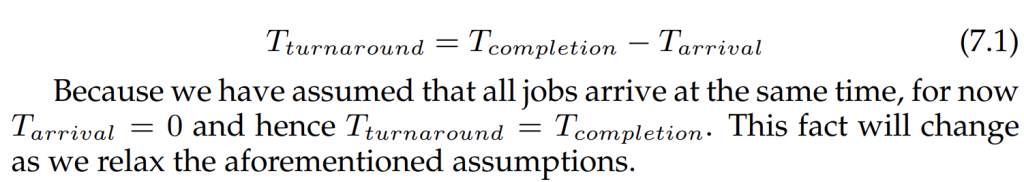
FIFO
The most basic algorithm we can implement is known as First In, First Out (FIFO) scheduling or sometimes First Come, First Served (FCFS).
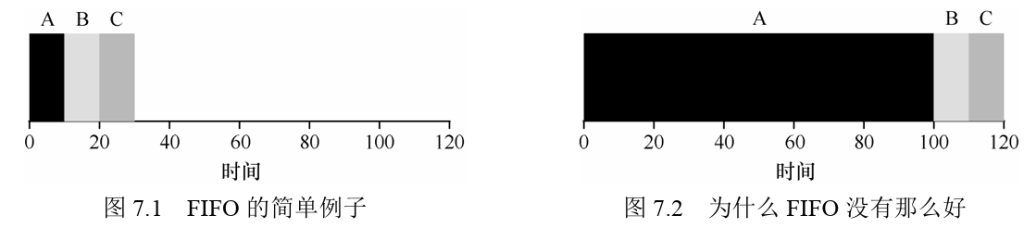
This problem is generally referred to as the convoy effect.

SJF
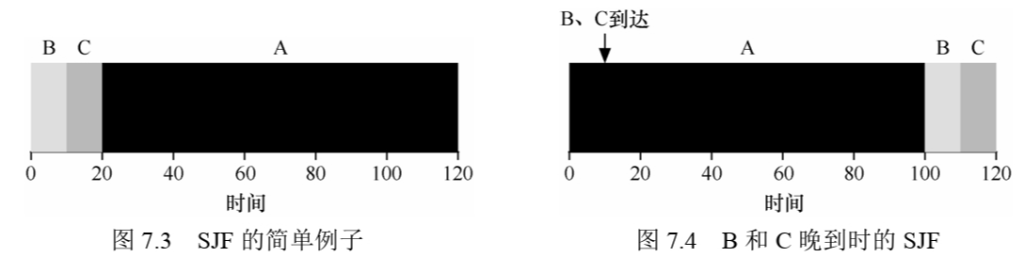
因此,我们找到了一个用SJF进行调度的好方法,但是我们的假设仍然是不切实际的。让我们放宽另一个假设。具体来说,我们可以针对假设2,现在假设工作可以随时到达,而不是同时到达。这导致了什么问题?(再次停下来想想……你在想吗?加油,你可以做到)在这里我们可以再次用一个例子来说明问题。现在,假设A在t = 0时到达,且需要运行100s。而B和C在t = 10到达,且各需要运行10s。用纯SJF,我们可以得到如图7.4所示的调度。但是假如BC并非同时到达同样存在问题
STCF
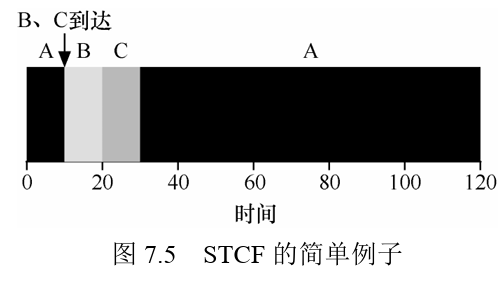
Fortunately, there is a scheduler which does exactly that: add preemption to SJF, known as the Shortest Time-to-Completion First (STCF) or Preemptive Shortest Job First (PSJF) scheduler [CK68]. Any time a new job enters the system, the STCF scheduler determines which of the remainingjobs (including the new job) has the least time left, and schedules that one. Thus, in our example, STCF would preempt A and run B and C to completion; only when they are finished would A’s remaining time be scheduled. Figure 7.5 shows an example.
new metric: response time

Round Robin
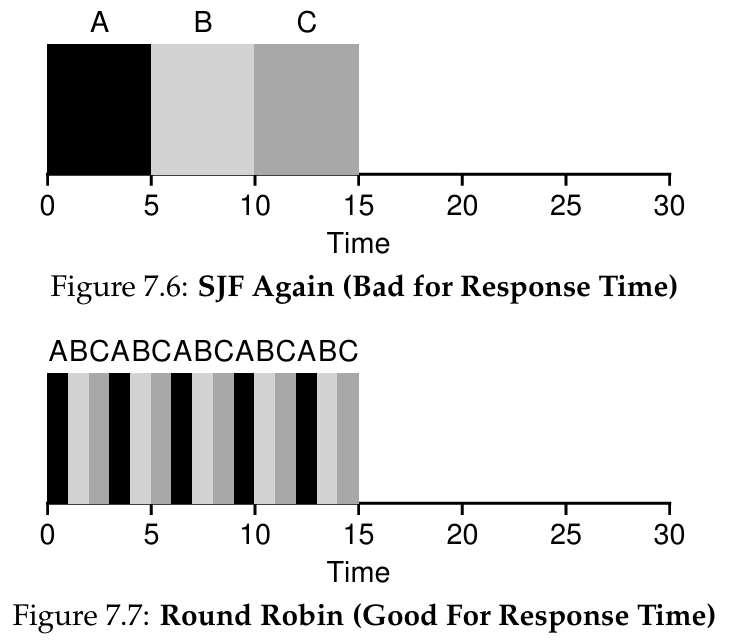
it is also called time-slicing,
。基本思想很简单:RR在一个时间片(time slice,有时称为调度量子,scheduling quantum)内运行一个工作,然后切换到运行队列中的下一个任务,而不是运行一个任务直到结束。它反复执行,直到所有任务完成。因此,系统设计者需要权衡时间片的长度,使其足够长,以便摊销(amortize)上下文切换成本,而又不会使系统不及时响应。

我们开发了两种调度程序。第一种类型(SJF、STCF)优化周转时间,但对响应时间不利。第二种类型(RR)优化响应时间,但对周转时间不利。
Incorporating I/O
Ascheduler clearly has a decision to make when a job initiates an I/O request, because the currently-running job won’t be using the CPU during the I/O; it is blocked waiting for I/O completion. If the I/O is sent to a hard disk drive, the process might be blocked for a few milliseconds or longer, depending on the current I/O load of the drive.
为了更好地理解这个问题,让我们假设有两项工作A和B,每项工作需要50ms的CPU时间。但是,有一个明显的区别:A运行10ms,然后发出I/O请求(假设I/O每个都需要10ms),而 B只是使用CPU 50ms,不执行I/O。调度程序先运行A,然后运行B(见图7.8)。
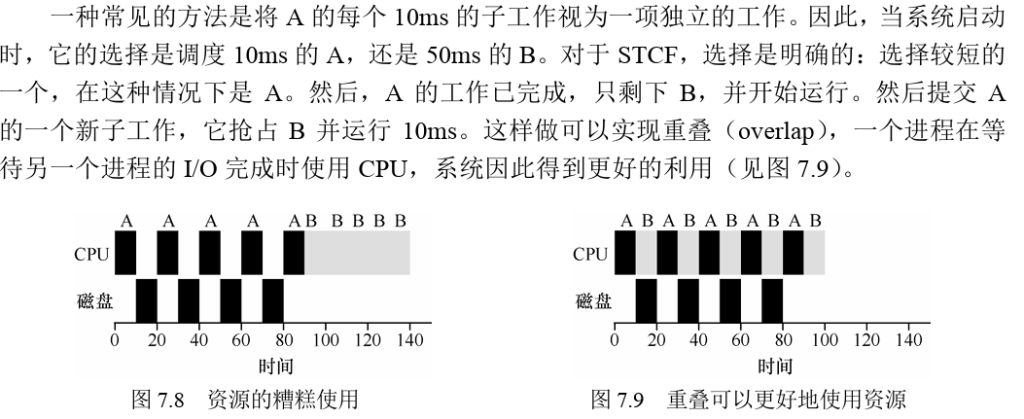
Scheduling: The Multi-Level Feedback Queue
The fundamental problem MLFQ tries to address is two-fold. First, it would like to optimize turnaround time, which, as we saw in the previous note, is done by running shorter jobs first; unfortunately, the OS doesn’t generally know how long a job will run for, exactly the knowledge that algorithms like SJF (or STCF) require. Second, MLFQ would like to make a system feel responsive to interactive users (i.e., users sitting and staring at the screen, waiting for a process to finish), and thus minimize response time; unfortunately, algorithms like Round Robin reduce response time but are terrible for turnaround time.


In our treatment, the MLFQ has a number of distinct queues, each assigned a different priority level. At any given time, a job that is ready to run is on a single queue. MLFQ uses priorities to decide which job
should run at a given time: a job with higher priority (i.e., a job on a higher queue) is chosen to run.
Thus, we arrive at the first two basic rules for MLFQ:
• Rule1: If Priority(A) > Priority(B), A runs (B doesn’t).
• Rule2: If Priority(A) = Priority(B), A & B run in RR.
我们必须决定,在一个工作的生命周期中,MLFQ如何改变其优先级(在哪个队列中)。要做到这一点,我们必须记得工作负载:既有运行时间很短、频繁放弃CPU的交互型工作,也有需要很多CPU时间、响应时间却不重要的长时间计算密集型工作。下面是我们第一次尝试优先级调整算法。
- Rule 3: When a job enters the system, it is placed at the highest priority (the topmost queue).
• Rule 4a: If a job uses up its allotment while running, its priority is reduced (i.e., it moves down one queue).
• Rule 4b: If a job gives up the CPU (for example, by performing an I/O operation) before the allotment is up, it stays at the same priority level (i.e., its allotment is reset).
实例:



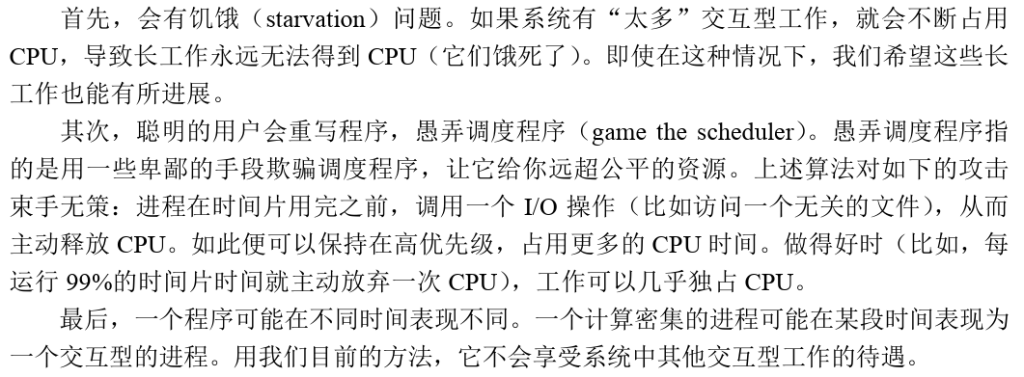
尝试:提升优先级
规则5:经过一段时间S,就将系统中所有工作重新加入最高优先级队列。
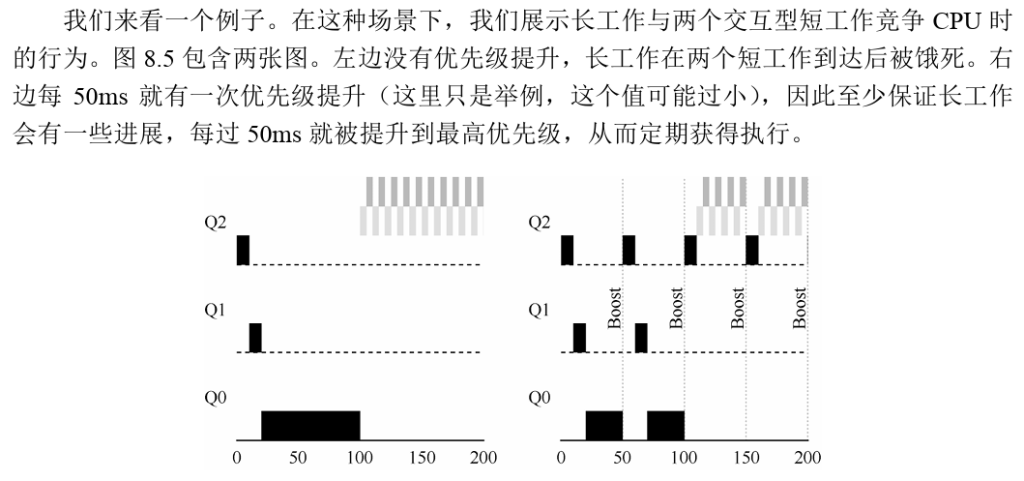
尝试3:使用更加合理的计时方式
这里的解决方案,是为MLFQ的每层队列提供更完善的CPU计时方式(accounting)。
调度程序应该记录一个进程在某一层中消耗的总时间,而不是在调度时重新计时。只要进
程用完了自己的配额,就将它降到低一优先级的队列中去。
规则 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次
CPU),就降低其优先级(移入低一级队列)。
关于MLFQ调度算法还有一个问题,其中之一就是如何配置一个调度程序,例如配置多少队列以及每一层队列的时间片配置多大?为了避免接问题以及进程行为变化,应该多久提升一次进程的优先级?
大多数的MLFQ变体都支持不同队列可变的时间片长度。高优先级队列通常只有较短的时间片(比如 10ms 或者更少),因而这一层的交互工作可以更快地切换。相反,

总结一下MLFQ优化之后的规则:
为了方便查阅,我们重新列在这里。
规则1:如果A的优先级 > B的优先级,运行A(不运行B)。
规则2:如果A的优先级 = B的优先级,轮转运行A和B。
规则3:工作进入系统时,放在最高优先级(最上层队列)。
规则 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次CPU),就降低其优先级(移入低一级队列)。
规则5:经过一段时间S,就将系统中所有工作重新加入最高优先级队列。


下面来看一个例子。假设有两个进程A和B,A拥有75张彩票,B拥有25张。因此我们希望A占用75%的CPU时间,而B占用25%。
通过不断定时地(比如,每个时间片)抽取彩票,彩票调度从概率上(但不是确定的)获得这种份额比例。抽取彩票的过程很简单:调度程序知道总共的彩票数(在我们的例子中,有100张)。调度程序抽取中奖彩票,这是从0和99①之间的一个数,拥有这个数对应的彩票的进程中奖。假设进程A拥有0到74共75张彩票,进程B拥有75到99的25张,中奖的彩票就决定了运行A或B。调度程序然后加载中奖进程的状态,并运行它。
彩票机制
一种方式是利用彩票货币(ticket currency)的概念。这种方式允许拥有一组彩票的用户以他们喜欢的某种货币,将彩票分给自己的不同工作。之后操作系统再自动将这种货币兑换为正确的全局彩票。比如,假设用户A和用户B每人拥有100张彩票。用户A有两个工作A1和A2,他以自己的货币,给每个工作500张彩票(共1000张)。用户B只运行一个工作,给它10张彩票(总共10张)。操作系统将进行兑换,将A1和A2拥有的A的货币500张,兑换成全局货币50张。类似地,兑换给B1的10张彩票兑换成100张。然后会对全局彩票货币(共200张)举行抽奖,决定哪个工作运行。
另一个有用的机制是彩票转让(ticket transfer)。通过转让,一个进程可以临时将自己的彩票交给另一个进程。这种机制在客户端/服务端交互的场景中尤其有用,在这种场景中,客户端进程向服务端发送消息,请求其按自己的需求执行工作,为了加速服务端的执行,客户端可以将自己的彩票转让给服务端,从而尽可能加速服务端执行自己请求的速度。服务端执行结束后会将这部分彩票归还给客户端。
最后,彩票通胀(ticket inflation)有时也很有用。利用通胀,一个进程可以临时提升或降低自己拥有的彩票数量。当然在竞争环境中,进程之间互相不信任,这种机制就没什么意义。一个贪婪的进程可能给自己非常多的彩票,从而接管机器。但是,通胀可以用于进程之间相互信任的环境。在这种情况下,如果一个进程知道它需要更多CPU时间,就可以增加自己的彩票,从而将自己的需求告知操作系统,这一切不需要与任何其他进程通信。
步长调度算法
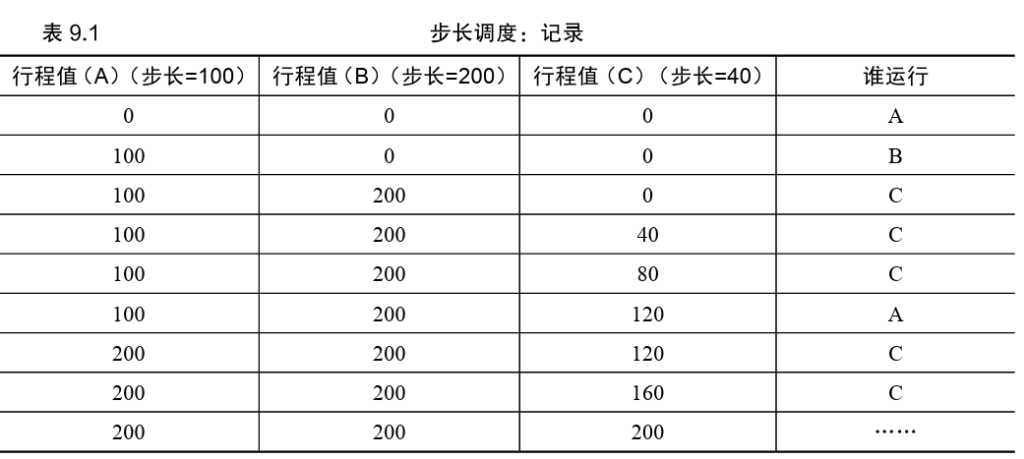
关于CPU虚拟化的总结



The Abstraction: Address Spaces(抽象:地址空间)
在早期,机器中存在的抽象很少,机器的物理内存就像下图一样存储
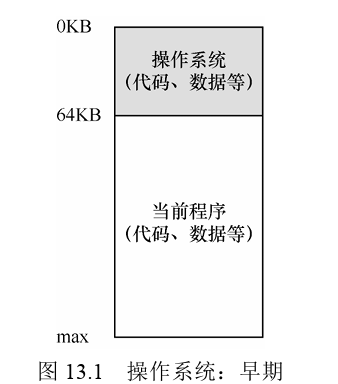
但在这种情况下机器收到物理较大的限制,并且由于机器昂贵,人们开始学会更有效地共享机器。Multiprogramming系统时代开启,多个进程在给定时间准备进行,比如在一个进程等待I/O操作的时候操作系统会切换这种进程增加了CPU的利用率、
但很快,人们对于机器有了更多的要求,分时系统的时代诞生了,即人们意识到批量计算的局限性,尤其是程序员本身厌倦了长时间的编译-调试循环,交互性比较重要。

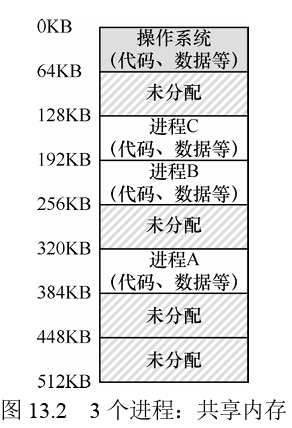
然而,我们必须将这些烦人的用户的需求放在心上。因此操作系统需要提供一个易用(easy to use)的物理内存抽象。这个抽象叫作地址空间(address space),是运行的程序看到的系统中的内存。理解这个基本的操作系统内存抽象,是了解内存虚拟化的关键。
一个进程的地址空间包含运行的程序的所有内存状态。比如:程序的代码(code,指令)必须在内存中,因此它们在地址空间里。当程序在运行的时候,利用栈(stack)来保存当前的函数调用信息,分配空间给局部变量,传递参数和函数返回值。最后,堆(heap)用于管理动态分配的、用户管理的内存,就像你从C语言中调用malloc()或面向对象语言(如C ++或Java)中调用new 获得内存。当然,还有其他的东西(例如,静态初始化的变量),但现在假设只有这3个部分:代码、栈和堆。
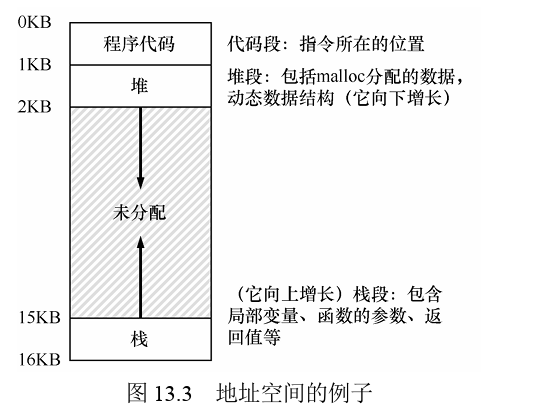
当操作系统这样做时,我们说操作系统在虚拟化内存(virtualizing memory),因为运行的程序认为它被加载到特定地址(例如 0)的内存中,并且具有非常大的地址空间(例如32 位或64位)。现实很不一样。
例如,当图13.2中的进程A尝试在地址0(我们将称其为虚拟地址,virtual address)执行加载操作时,然而操作系统在硬件的支持下,出于某种原因,必须确保不是加载到物理地址0,而是物理地址320KB(这是A载入内存的地址)。这是内存虚拟化的关键,这是世界上每一个现代计算机系统的基础。
Part II 并发
永远不要忘记具体概念。好吧,事实证明,存在某些类型的程序,我们称之为多线程(multi-threaded)应用程序。每个线程(thread)都像在这个程序中运行的独立代理程序,代表程序做事。但是这些线程访问内存,对于它们来说,每个内存节点就像一个桃子。如果我们不协调线程之间的内存访问,程序将无法按预期工作。
在抽象这一章节,我们以及看到了如何将一个CPU变成多个虚拟的CPU,从而支持多个程序同时运行的假象,还看到了如何为每个进程创造巨大的私有的虚拟内存,这种地址空间的抽象使得每个程序“好像”拥有自己的内存,实际上是一种物理内存的复用
本章将介绍为单个运行进程提供的新抽象:线程(thread)。经典观点是一个程序只有
一个执行点(一个程序计数器,用来存放要执行的指令),但多线程(multi-threaded)程序
会有多个执行点(多个程序计数器,每个都用于取指令和执行)。换一个角度来看,每个线
程类似于独立的进程,只有一点区别:它们共享地址空间,从而能够访问相同的数据。
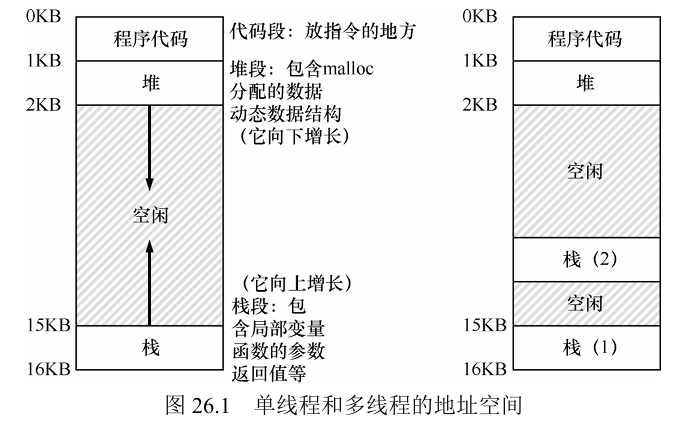
单线程和多线程的地址空间如上图,线程和进程之间的一个主要区别在于栈,在简单的传统进程地址空间模型 [我们现在可以称之为单线程(single-threaded)进程] 中,只有一个栈,通常位于地址空间的底部(见左图)。然而,在多线程的进程中,每个线程独立运行,当然可以调用各种例程来完成正在执行的任何工作。不是地址空间中只有一个栈,而是每个线程都有一个栈。
与进程相比,线程之间的上下文切换还有一点主要区别:地址空间保持不变(即不需要切换当前使用的页表)。
include<stdio.h>
#include<assert.h>
#include<pthread.h>
void *mythread(void *arg) {
printf("%s\n", (char *) arg);
return NULL;
}
int main(int argc,char *argv[]){
pthread_t p1,p2;
int rc;
printf("main: begin\n");
rc = pthread_create(&p1,NULL,mythread,"A");
assert(rc == 0);
rc = pthread_create(&p2,NULL,mythread,"B");
assert(rc == 0);
rc = pthread_join(p1,NULL);
assert(rc == 0);
rc = pthread_join(p2,NULL);
assert(rc == 0);
printf("main: end\n");
return 0;
}让我们来看看这个小程序的可能执行顺序。
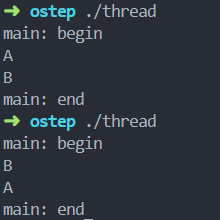
但请注意,这种排序不是唯一可能的顺序。这里面大多的程序取决于进程的调度,比如说进程创建之后可能立刻运行,也可能一直不运行
上面演示的简单线程示例非常有用,它展示了线程如何创建,根据调度程序的决定,它们如何以不同顺序运行。但是,它没有展示线程在访问共享数据时如何相互作用。
这也恰恰是多线程糟糕的地方:共享数据
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include "common.h"
#include "common_threads.h"
int max;
volatile int counter = 0; // shared global variable
void *mythread(void *arg) {
char *letter = arg;
int i; // stack (private per thread)
printf("%s: begin [addr of i: %p]\n", letter, &i);
for (i = 0; i < max; i++) {
counter = counter + 1; // shared: only one
}
printf("%s: done\n", letter);
return NULL;
}
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "usage: main-first <loopcount>\n");
exit(1);
}
max = atoi(argv[1]);
pthread_t p1, p2;
printf("main: begin [counter = %d] [%x]\n", counter,
(unsigned int) &counter);
Pthread_create(&p1, NULL, mythread, "A");
Pthread_create(&p2, NULL, mythread, "B");
// join waits for the threads to finish
Pthread_join(p1, NULL);
Pthread_join(p2, NULL);
printf("main: done\n [counter: %d]\n [should: %d]\n",
counter, max*2);
return 0;
}
以下是关于代码的一些说明。首先,如Stevens建议的[SR05],我们封装了线程创建和合并例程,以便在失败时退出。对于这样简单的程序,我们希望至少注意到发生了错误(如果发生了错误),但不做任何非常聪明的处理(只是退出)。因此,Pthread_create()只需调用pthread_create(),并确保返回码为 0。如果不是,Pthread_create()就打印一条消息并退出。
最后,最重要的是,我们现在可以看看每个工作线程正在尝试做什么:向共享变量计数器添加一个数字,并在循环中执行1000万(107)次。因此,预期的最终结果是:20000000。
不过我们应该会失落地发现,我们得到的结果很少很少和目标一致并且产生错误,而且得到不同的结果!有一个大问题:为什么会发生这种情况?
核心问题:不可控的调度
设想我们的两个线程之一(线程1)进入这个代码区域,并且因此将要增加一个计数器。它将counter 的值(假设它这时是50)加载到它的寄存器eax中。因此,线程1的eax = 50。然后它向寄存器加1,因此eax = 51。现在,一件不幸的事情发生了:时钟中断发生。因此,操作系统将当前正在运行的线程(它的程序计数器、寄存器,包括eax等)的状态保存到线程的TCB。
这里展示的情况称为竞态条件(race condition):结果取决于代码的时间执行。由于运气不好(即在执行过程中发生的上下文切换),我们得到了错误的结果。事实上,可能每次都会得到不同的结果。因此,我们称这个结果是不确定的(indeterminate),而不是确定的(deterministic)计算(我们习惯于从计算机中得到)。不确定的计算不知道输出是什么,它在不同运行中确实可能是不同的。
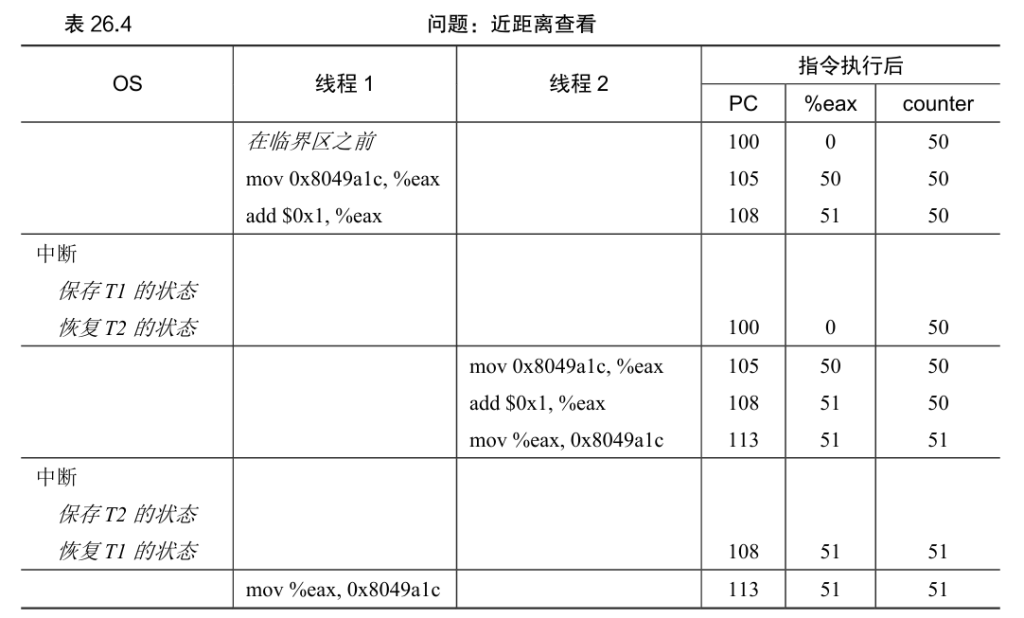
我们真正想要的代码就是所谓的互斥(mutual exclusion)。这个属性保证了如果一个线程在临界区内执行,其他线程将被阻止进入临界区。
原子性愿望

补充:关键并发术语
临界区、竞态条件、不确定性、互斥执行
这4个术语对于并发代码来说非常重要,我们认为有必要明确地指出。 请参阅Dijkstra的一些早期著作[D65,D68]了解更多细节。
临界区(critical section)是访问共享资源的一段代码,资源通常是一个变量或数据结构。
竞态条件(race condition)出现在多个执行线程大致同时进入临界区时,它们都试图更新共享的数据结构,导致了令人惊讶的(也许是不希望的)结果。
不确定性(indeterminate)程序由一个或多个竞态条件组成,程序的输出因运行而异,具体取决于哪些线程在何时运行。这导致结果不是确定的(deterministic),而我们通常期望计算机系统给出确定的结果。
为了避免这些问题,线程应该使用某种互斥(mutual exclusion)原语。这样做可以保证只有一个线程进入临界区,从而避免出现竞态,并产生确定的程序输出。
还有一个问题:等待另一个线程
我们不仅要研究如何构建对同步原语的支持来支持原子性,还要研究支持在多线程程序中常见的睡眠/唤醒交互的机制
插叙:线程API
编写多线程程序的第一步就是创建新线程,因此必须存在某种线程创建接口。在POSIX 中,很简单:
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void *), void *arg);第三个参数最复杂,但它实际上只是问:这个线程应该在哪个函数中运行?在 C 中,我们把它称为一个函数指针(function pointer),这个指针告诉我们需要以下内容:一个函数名称(start_routine),它被传入一个类型为void *的参数(start_routine 后面的括号表明了这一点),并且它返回一个void *类型的值(即一个void指针)。
第四个参数则是为了传入任何类型的结果作为返回值,所以是void*
上面的例子展示了如何创建一个线程。但是,如果你想等待线程完成,会发生什么情况呢?
你需要做一些特别的事情来等待完成。具体来说,你必须调用函数pthread_join()。
void *mythread(void *arg) {
int m = (int) arg;
printf("%d\n", m);
return (void *) (arg + 1);
}
int main(int argc, char *argv[]) {
pthread_t p;
int rc, m;
Pthread_create(&p, NULL, mythread, (void *) 100);
Pthread_join(p, (void **) &m);
printf("returned %d\n", m);
return 0;
}锁
除了线程创建和join之外,POSIX线程库提供的最有用的函数集,可能是通过锁(lock)来提供互斥进入临界区的那些函数。这方面最基本的一对函数是:
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
对于 POSIX 线程,有两种方法来初始化锁。一种方法是使用 PTHREAD_MUTEX_INITIALIZER,如下所示:
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;这样做会将锁设置为默认值,从而使锁可用。初始化的动态方法(即在运行时)是调用pthread_mutex_init(),如下所示
int rc = pthread_mutex_init(&lock, NULL);
assert(rc == 0); // always check success!
条件变量(信号量)
当线程之间必须发生某种信号时,如果一个线程在等待另一个线程继续执行某些操作,条件变量就很有用。希望以这种方式进行交互的程序使用两个主要函数:
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
int pthread_cond_signal(pthread_cond_t *cond);
请注注,有时候线程之间不用条件变量和锁,用一个标记变量会看起来很简单,很吸
引人。例如,我们可以重写上面的等待代码,像这样:
while (ready == 0)
;
// spin
相关的发信号代码看起来像这样:
ready = 1;
千万不要这么做。首先,多数情况下性能差(长时间的自旋浪费CPU)。其次,容易出错。

锁
锁的基本思想

lock()和 unlock()函数的语义很简单。调用lock()尝试获取锁,如果没有其他线程持有锁(即它是可用的),该线程会获得锁,进入临界区。这个线程有时被称为锁的持有者(owner)。如果另外一个线程对相同的锁变量(本例中的mutex)调用 lock(),因为锁被另一线程持有,该调用不会返回。这样,当持有锁的线程在临界区时,其他线程就无法进入临界区。
POSIX 库将锁称为互斥量(mutex),因为它被用来提供线程之间的互斥。即当一个线程在临界区,它能够阻止其他线程进入直到本线程离开临界区。因此,如果你看到下面的POSIX 线程代码,应该理解它和上面的代码段执行相同的任务(我们再次使用了包装函数来检查获取锁和释放锁时的错误)。
