

数据结构Final汇总
线性表、树、图必有题。散列表、并查集、优先队列每次不一定
第一章
数据的概念不管
数据结构的概念看看(一般不考概念题)
线性结构和非线性结构的意思要掌握(不会填空)
数据类型不考
面向对象的概念要掌握(一般不会专门考概念)
算法的概念看一下,性质有一年考过
算法和程序的区别应该不考
数学公式不考
数学归纳法不做重点,也可以不看
递归看一下
泛型不做重点,主要是能读懂就行,不会要求写
泛型的机制也不是重点
第二章
时间和空间复杂度知道就行
重点是大O表示法,会结合排序算法考,或给个算法问复杂度,或要求写一个复杂度尽可能低的算法
最优、最差、平均(只要求等概率)复杂度得知道
O,Ω等符号代表的意思得清楚
排序算法都要求掌握
折半查找要的
分治法看看,一般来说也不是特别大的重点
第三章
明白线性表是什么概念
基本概念看看就行
数组实现和单链表实现都要掌握
单链表的操作是必须掌握的基本
带表头节点的会出现
双链表知道一下就行,概率不大
循环链表知道有这个结构
静态链表要求掌握
栈和队列要认真看
栈和队列的基本操作
难点在于出应用场景,要求用栈或队列解决
第四章
树的基本概念看看
二叉树考的概率很高
概念过过
完全二叉树的数组实现、链接实现
树的遍历、由遍历构建树
树的遍历的非递归写法要求读不要求写
字符串看看
广义表基本不考,可以不掌握
森林的遍历
线索树要求的
huffman树时不时考
二叉搜索树大多数时候直接考AVL
证明不考,知道结论就行
B-Tree会考(很大概率)
m路搜索树和B-Tree的不同可能会考
B-Tree不要求代码
第五章
有时候会有一两题
知道装载因子
专门为考试学的几个散列函数
碰撞解决方案及其搜索长度
rehashing知道过程就行
分离链没有线性探测考的多
第六章
概念知道是什么东西就行
堆的上滤下滤操作
堆的enqueue、dequeue
O(n)复杂度的建堆
堆排序
证明不需要,记结论
第七章
今年考并查集
等价类的概念不考
第八章
概念和树一样,过一下就行
邻接矩阵和邻接表肯定要掌握
邻接多重表几乎不考(应该卷子里没有,如果没记错的话)
遍历肯定要掌握
连通图和连通分量肯定得知道
三大类问题的算法肯定得会
AOV和AOE也常考,要掌握拓扑排序和算关键路径
第九章
都要会
折半插入一般不考
希尔排序得知道主流程,不考代码,证明当然不考
Radix排序一般也不太考
Contents
List列表(线性表为主)
AbstractDateType LinearList
{ instances
ordered finite collections of zero or more elements
operations
Create();
Destroy();
IsEmpty();
Find(k,x);
Delete(k,x);
Output(out);
Length();
Search(x);
Insert(k,x);
}
serveral Implementations多种实现
使用数组:
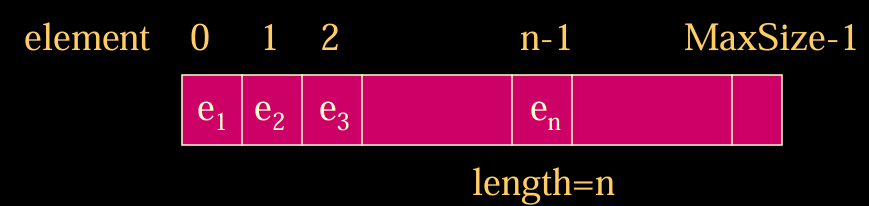
search(x): 复杂度为On(可以遍历,或者考虑有序集二分)
remove(a,x):复杂度为On(移除后前移)
insert(x,i):复杂度为On
使用链表
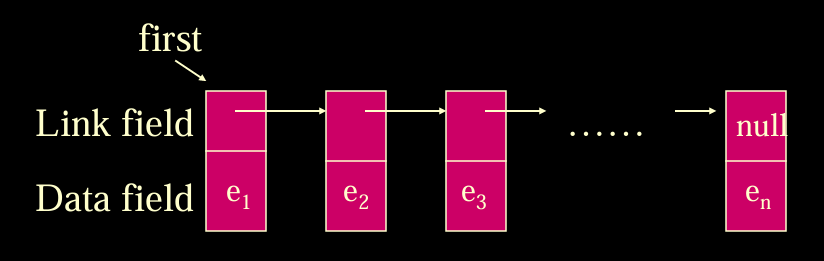
最后一个节点为空
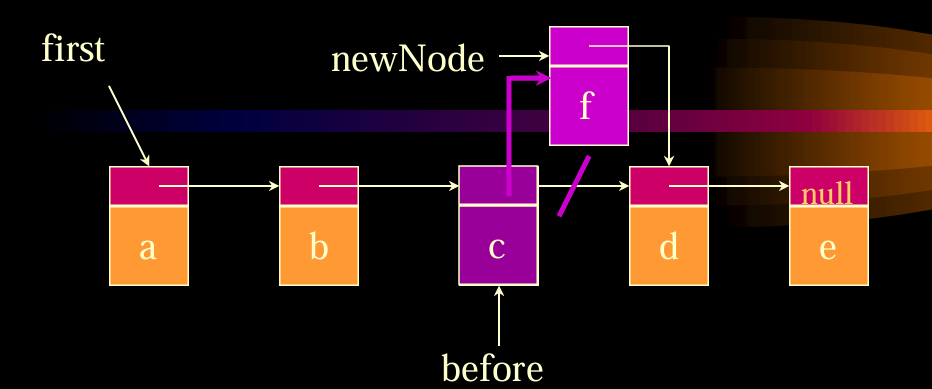
delete删除操作:
first get to node just before node to be removed
before= first .link;直到够到需要删除的节点之后,before .link = before .link .link;
insert插入操作:首先new一个chainNode对象,然后放在first位置,first find node whose index is 3,然后插入这个

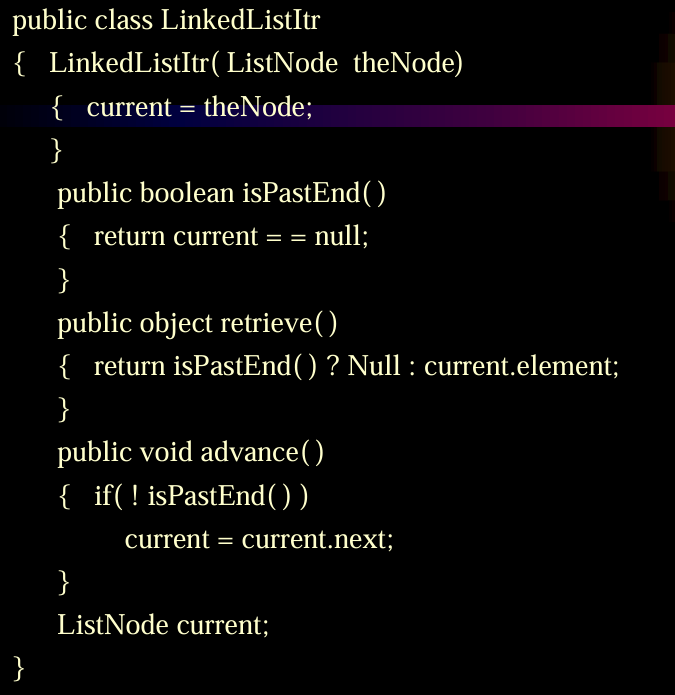
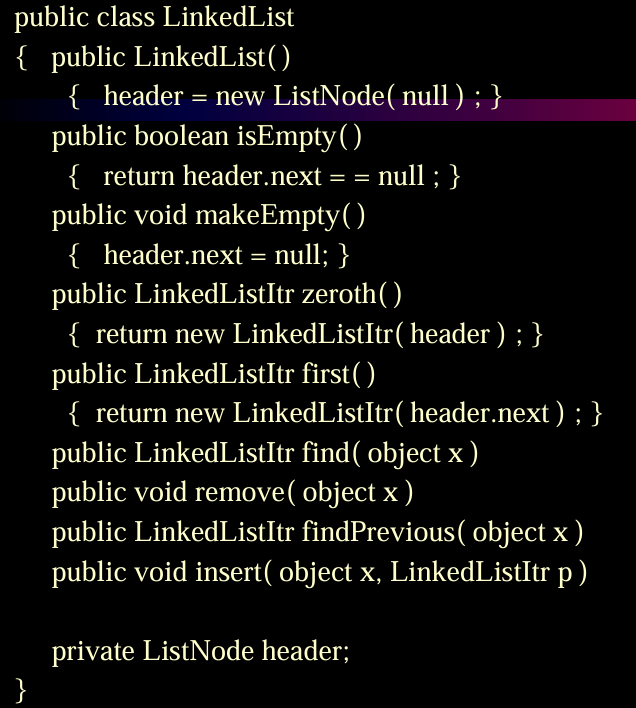

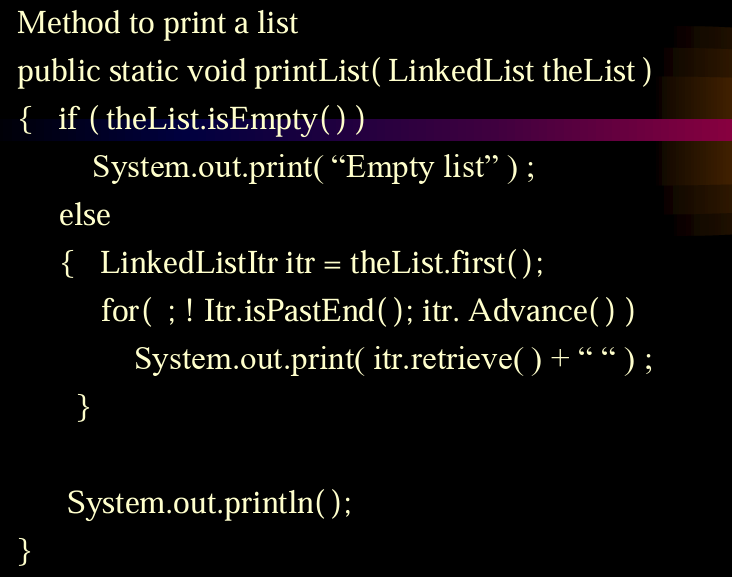
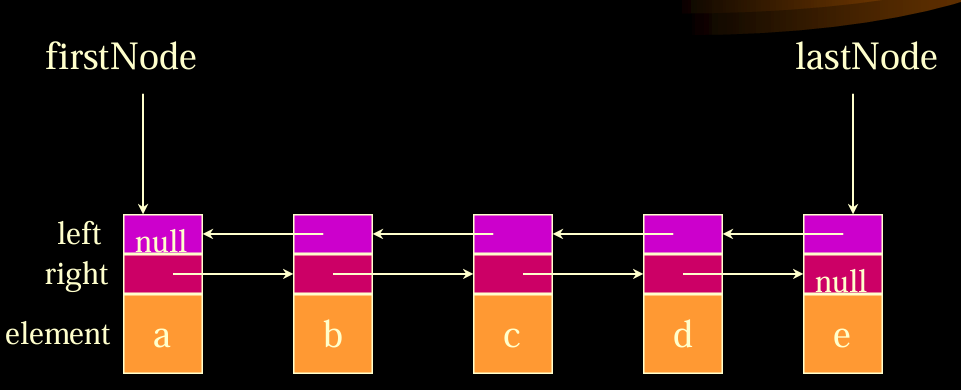
双向链表
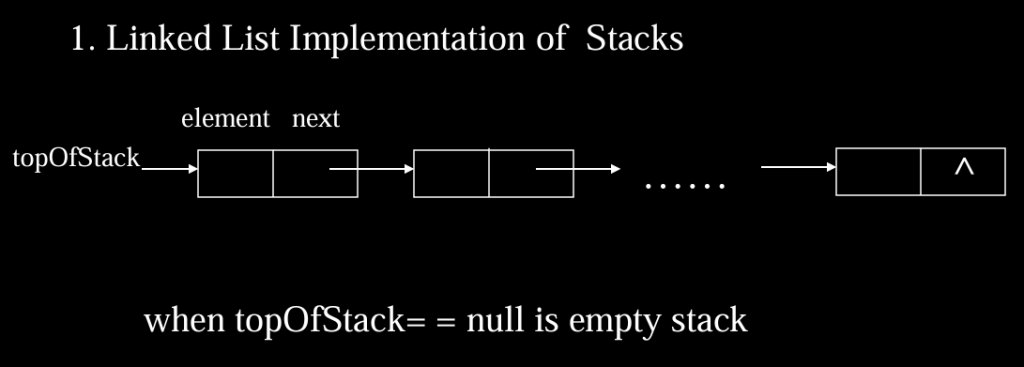
栈与队列(LIFO&FIFO表)
AbstractDataType Stack{
instances
list of elements; one end is called the bottom; the other is the top;
operations
Create():Create an empty stack;
IsEmpty():Return true if stack is empty,return false otherwise
IsFull ():Return true if stack if full,return false otherwise;
Top():return top element of the stack;
Add(x): add element x to the stack;
Delete(x):Delete top element from stack and put it in x;
public class StackLi
{ public StackLi( ){ topOfStack = null; }
public boolean isFull( ){ return false; }
public boolean isEmpty( ){ return topOfStack = = null; }
public void makeEmpty( ){ topOfStack = null; }
public void push( object x )
public object top( )
public void pop( ) throws Underflow
public object topAndPop( )
private ListNode topOfStack;
}
public void push( object x )
{ topOfStack = new ListNode( x, topOfStack );
}
public object top( )
{ if( isEmpty( ) )
return null;
return topOfStack.element;
}
public void pop( ) throws Underflow
{ if( isEmpty( ) )
throw new Underflow( );
topOfStack = topOfStack.next;
}
public object topAndPop( )
{ if( isEmpty( ) )
return null;
object topItem = topOfstack.element;
topOfStack = topOfStack .next;
return topItem;
}
队列(Queue)
AbstractDataType Queue
{
instances
ordered list of elements;one end is called the front; the other is the rear;
operations
Create(): Create an empty queue;
IsEmpty(): Return true if queue is empty,return false otherwise;
IsFull(): return true if queue is full, return false otherwise;
First(): return first element of the queue;
Last(): return last element of the queue;
Add(x): add element x to the queue;
Delete(x): delete front element from the queue and put it in x;
}
使用数组实现:最好采取环形的方式(防止free space挤在一端)
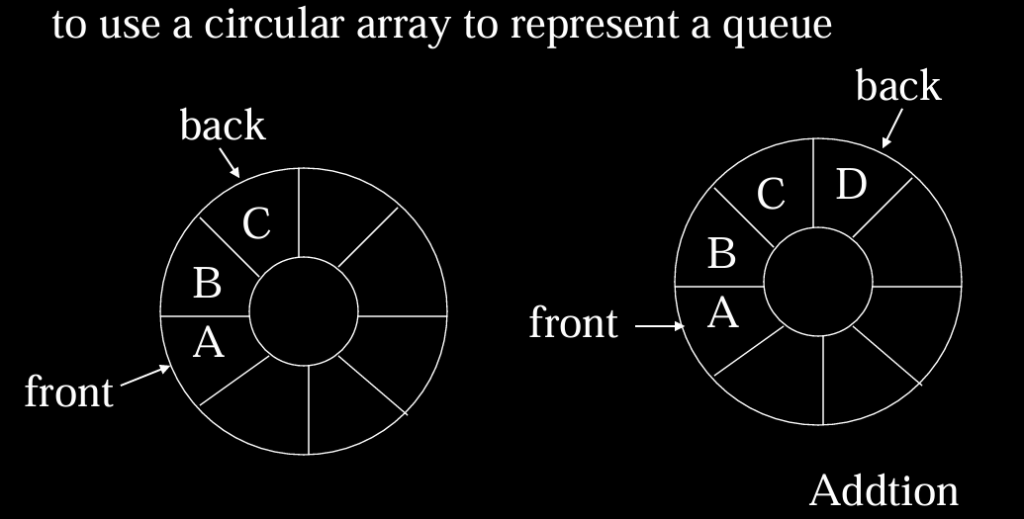

Public class QueueAr
{
public QueueAr( )
public QueueAr( int capacity )
public boolean isEmpty( ){ return currentsize = = 0; }
public boolean isfull( ){ return currentSize = = theArray.length; }
public void makeEmpty( )
public Object getfront( )
public void enqueue( Object x ) throw Overflow
private int increment( int x )
private Object dequeue( )
private Object [ ] theArray;
private int currentSize;
private int front;
private int back;
static final int DEFAULT_CAPACITY = 10;
}
链表实现
template<class T>class LinkedQueue
{ public:
LinkedQueue(){front=back=0;}
~LinkedQueue();
bool IsEmpty()const{return ((front)?false:true);}
bool IsFull()const;
T First()const;
T Last()const;
LinkedQueue<T>&Add(const T& x);
LinkedQueue<T>& Delete(T& x);
private:
Node<T>*front; Node<T>*back;
};树(Tree)
节点的度:子节点个数
树的度:节点度的最大值
一些性质:有n个元素的二叉树有n-1条边
如果叶子的个数是n0,度数为2的节点个数是n-1
The height of a binary tree that contains n(n>=0) element is at most n-1 and at least log2(n+1)-1(向上取整)
完全二叉树:(堆)
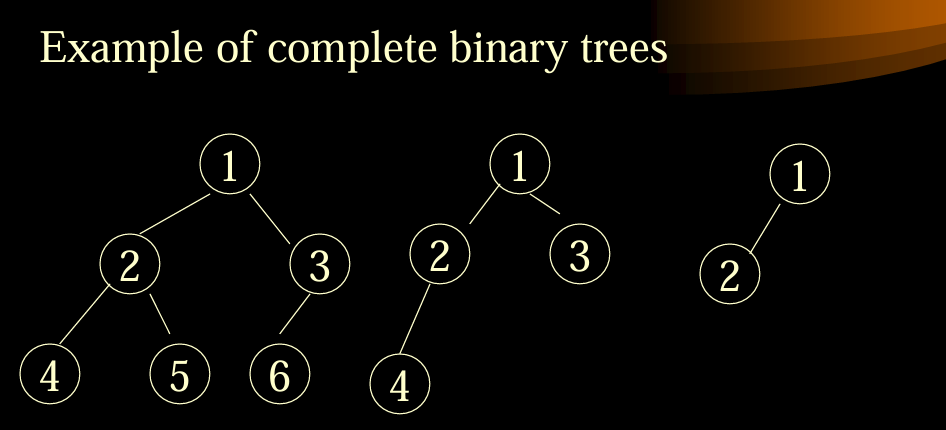

(这些性质也是使用数组存放堆的基本原理)
因此非完全二叉树使用数组表达时可以把对应位置空出
——链表表达的二叉树

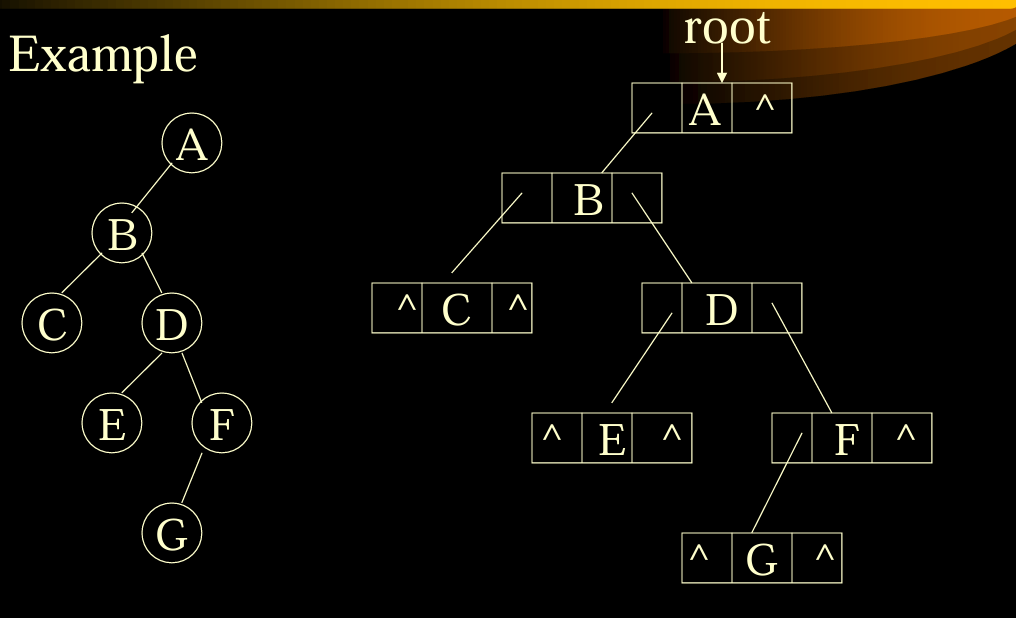
class BinaryNode {
BinaryNode(){Left=Right=0;}
BinaryNode(Object e)
{element=e; Left=Right=0;}
BinaryNode(Object e, BinaryNode l, BinaryNode r)
{element=e; Left=l; Right=r; }
Object element;
BinaryNode left;//left subtree
BinaryNode right;//right subtree
};template<class T>class BinaryTree {
public:
BinaryTree(){root=0;};
~BinaryTree(){};
bool IsEmpty()const
{return ((root)?false:true);}
bool Root(T& x)const;
void MakeTree(const T& data, BinaryTree<T>& leftch, BinaryTree<T>& rightch);
void BreakTree(T& data , BinaryTree<T>& leftch, BinaryTree<T>& rightch);
void PreOrder(void(*visit)(BinaryNode<T>*u)) {PreOrder(visit, root);}
void InOrder(void(*visit)(BinaryNode<T>*u)) {InOrder(visit, root);}
void PostOrder (void(*visit)(BinaryNode<T>*u)) {PostOrder(visit, root);}
void LevelOrder (void(*visit)(BinaryNode<T> *u));
private:
BinaryNode<T>* root;
void PreOrder(void(*visit)(BinaryNode<T> *u), BinaryNode<T>*t);
void InOrder(void(*visit)(BinaryNode<T> *u), BinaryNode<T>*t);
void PostOrder(void(*visit) (BinaryNode<T> *u), BinaryNode<T>*t);
};四种遍历方式:
1先序遍历
//递归实现先序遍历
template<class T>
void PreOrder(BinaryNode<T>* t) {
// preorder traversal of *t.
if(t){
visit(t);
PreOrder(t->Left);
PreOrder(t->Right);
}
}2中序遍历
template<class T>
void InOrder(BinaryNode<T>* t) {
if(t){
InOrder(t->Left);
visit(t);
InOrder(t->Right);
}
}
//非递归使用stack实现中序遍历
void Inorder(BinaryNode <T>*t){
Stack<BinaryNode<T>*> s(10);
BinaryNode<T>*p = t;
for (;;){
//无条件进行循环
while(p!=NULL){
//一直进行压栈,直到最左下部分
s.push(p);
p = p->Left;
}
if(!s.IsEmpty()){
//出栈输出,然后指向右子树,之后重复上面计算到右子树的最左边的节点。
p = s.pop();
cout << p->element;
p = p->Right;
}else
return;
}
}后序遍历
template<class T>
void InOrder(BinaryNode<T>* t) {
if(t){
InOrder(t->Left);
InOrder(t->Right);
visit(t);
}
}
//非递归实现后序遍历
//结点的实现
struct StkNode {
BinaryNode <T> * ptr;
int tag;//用来标记是否标记过了,第一次进栈为1,第二次进栈为2.
}
//非递归实现后序遍历
void Postorder(BinaryNode <T> * t) {
Stack <StkNode<T>> s(10);
StkNode<T> Cnode;
BinaryNode<T>*p = t;
for(;;) {
//优先访问到最左下
while (p!=NULL){
Cnode.ptr = p;
Cnode.tag = 0;
s.push(Cnode);
p = p->Left;
}
//将最左下结点出栈
Cnode = s.pop();
p = Cnode.ptr;
while (Cnode.tag == 1)//从右子树回来
{
//如果已经被访问一次了才进行输出
cout << p->element;
if (!s.IsEmpty()){
Cnode = s.pop();
p = Cnode.ptr;
}else{
//访问结束
return;
}
}
Cnode.tag = 1;//从左子树遍历完,而右子树还没有动。
s.push(Cnode);
p = p->Right;//从左子树回来
}//for
} or
void PostOrder(BiTree T){
InitStack(S);
p=T;
r=NULL;
while(p!=NULL||!IsEmpty(s)){
if(p!=NULL){ //走到最左边
push(S,p);
p=p->lchild;
}
else{ //向右
GetTop(S,p); //读栈顶节点(非出栈)
if(p->rchild&&p->rchild!=r){ //若右子树存在,且未被访问过
p=p->rchild; //转向右
}
else{ //否则弹出结点并访问
pop(S,p);
visit(p->data); //访问该结点
r=p; //记录最近访问的结点
p=NULL; //结点访问完后,重置p指针
}
}
}Thread Tree 线索树
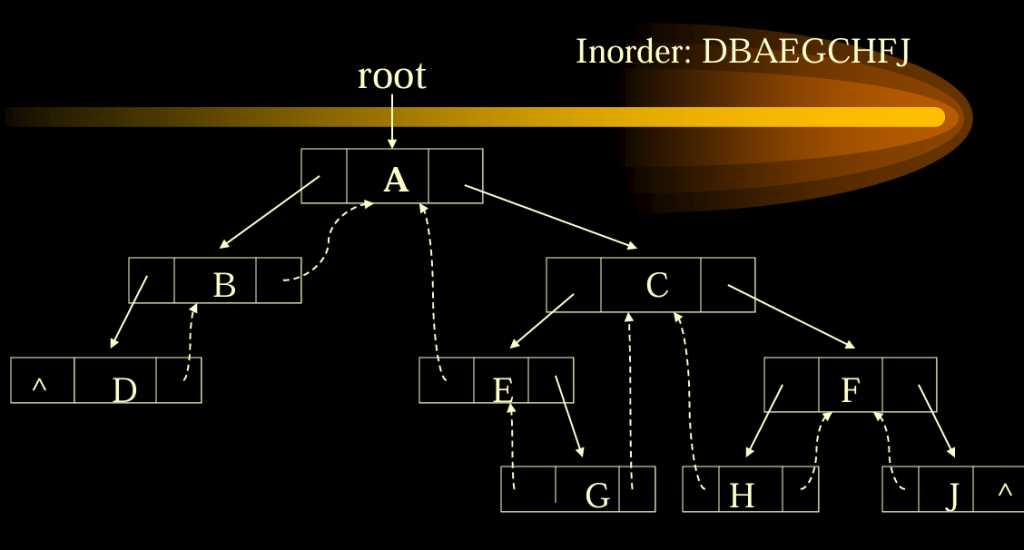

中序遍历的线索树
leftchild leftthread data rightthread rightchild线索树的结点结构
template<class Type>
ThreadNode<Type>* ThreadInorderIterator<Type>::First( )
{
while (current->leftThread= =0) current=current->leftchild;
return current;
}
template<class Type>
ThreadNode<Type>* ThreadInorderIterator<Type>::Next( )
{
ThreadNode<Type>* p=current->rightchild;
if(current->rightThread= =0)
while(p->leftThread= =0) p=p->leftchilld;
current=p;
return current;
}
template<class Type>
void ThreadInorderIterator<Type>:: Inorder( )
{
ThreadNode<Type> *p;
for ( p=First( ); p!=NULL; p=Next( ))
cout<< p->data<<endl;
}
构造线索树
Void Inthread(threadNode<T> * T)
{ stack <threadNode <T> *> s (10)
ThreadNode <T> * p = T ; ThreadNode <T> * pre = NULL;
for ( ; ; )
{ 1.while (p!=NULL)
{ s.push(p); p = p ->leftchild; }
2.if (!s.IsEmpty( ))
{
p = s.pop;
if (pre != NULL)
{ if (pre ->rightchild = = NULL)
{ pre ->rightchild = p; pre ->rightthread = 1;}
if ( p -> leftchild = = NULL)
{ p -> leftchild = pre ; p ->leftthread = 1; }
}
pre = p ;
p = p -> rightchild ;
}
else return;
}//for
}
树的应用
哈夫曼树
- 增长树(使得原来的树的每一个度数都为2)
- 对原二叉树中度为1的结点,增加一个空树叶
- 对原二叉树中的树叶,增加两个空树叶
- 外通路长度(外路径)E 根到每个外结点(增长树的叶子)的路径长度的总和(边数)
- E = 3+3+2+3+4+4+3+3=25,如右上图例
- 内通路长度(内路径)I:根到每个内结点(非叶子)的路径长度的总和(边数)。原来的树上每一个节点到树根的长度的综合
- I=2+1+0+3+2+2+1=11 如右上图例
- 结点的带权路径长度:一个结点的权值与结点的路径长度的乘积。
- 每个结点的权重占有一定的值
- 带权的外路径长度:各叶结点的带权路径长度之和。
- 带权的内路径长度:各非叶结点的带权路径长度之和。
Huffman算法
- 思想:权大的外结点靠近根,权小的远离根。
- 算法:从m个权值中找出两个最小值W1,W2构成
二叉搜索树(AVL)
基本性质:每一个元素都含有一个关键字,并且每一个元素都有独一无二的关键字
一个树的左子树的关键字小于根中的关键字
一个树的右子树的关键字大于根中的关键字
二叉搜索树需要满足的事情:在很大的数据量下,要能够很快的进行增删查改。这也就是二叉搜索树的优越性。
public class BinarySearchTree {
public BinarySearchTree(){ root = null; }
public void makeEmpty(){ root = null; }
public boolean isEmpty(){ return root == null;}
public Comparable find( Comparable x )
{return elementAt( find( x, root));}
public Comparable findMin()
{return elementAt( findMin( root ) );}
public Comparable findMax()
{return elementAt( findMax( root ) );
public void insert( Comparable x )
{root = insert( x, root );}
public void remove( Comparable x ) {root = remove( x, root ); }
public void printTree()//都是外部接口
private BinaryNode root;
private Comparable elementAt( BinaryNode t ){ return t == null ? Null : t.element; }
private BinaryNode find( Comparable x, BinaryNode t )
private BinaryNode findMin( BinaryNode t )
private BinaryNode findMax( BinaryNode t )
private BinaryNode insert( Comparable x, BinaryNode t )
private BinaryNode remove( Comparable x, BinaryNode t )
private BinaryNode removeMin( BinaryNode t )
private void printTree( BinaryNode t )
}
//查找某个元素的算法
private BinaryNode find( Comparable x, BinaryNode t ) {
if( t == null )
return null;
if( x.compareTo( t.element ) < 0 )
return find( x, t.left );
else if( x.compareTo( t.element ) > 0 )
return find( x, t.right );
else
return t;//Match
}
//查找值最小的结点
//使用递归查找结点
private BinaryNode findMin( BinaryNode t ) {
if( t == null )
return null;
else if( t.left == null )
return t;
return findMin( t.left );
}
//迭代找最小结点
private BinaryNode findMin(BinaryNode t){
if(t != null){
while(t.left != null){
t = t.left;
}
}
return t;
}
//递归找到最大结点
private BinaryNode findMax( BinaryNode t){
if(t == null){
return null;
}else if(t.right == null){
return t;
}
return findMax(t.right);
}
//迭代找到最大结点
private BinaryNode findMax( BinaryNode t ) {
if( t != null )
while( t.right != null )
t = t.right;
return t;
}
//将数值插入固定位置的算法
private BinaryNode insert( Comparable x, BinaryNode t ) {
//先查找一次,如果找到了就不用进行查找
if( t == null )
t = new BinaryNode( x, null, null );
else if( x.compareTo( t.element ) < 0 )
t.left = insert( x, t.left );
else if( x.compareTo( t.element ) > 0 )
t.right = insert( x, t.right );
else ;//duplicate; do nothing
return t;
}- 最坏的情况就是把一个有序的数列添加进入到空的二叉搜索树中去。
如何删除:
- 如果结点本身不在树内,那么不需要删除
- 如果结点本身在树里面,删除需要分类
- 无子树:删除叶节点
- 一颗子树:直接连接
- 两颗子树:可以选择左子树的最大结点作为新结点
AVL tree自平衡的二叉搜索树
- AVL树是一个二叉搜索树
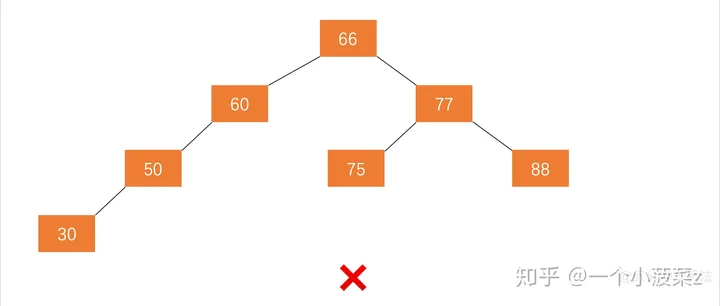
- AVL树的每一个节点满足|hL-hR|<=1 where hL and hR are the heights of TL(left subtree) and TR(right subtree),respectively.对于每一个结点,其左子树和右子树的高度之差不超过1
- 注:树叶之间之差未必小于一,但是一个节点的左右子树的高度不能大于一
例如图 2.1 不是平衡二叉树,因为结点 60 的左子树不是平衡二叉树
class AVLNode {
AVLNode(Comparable theElement) {
this( theElement, null, null);
}
AVLNode(Compalable theElement, AVLNode lt, AVLNode rt) {
element = theElement;
left = lt;
right = rt;
height = 0;
}
Comparable element;
AVLNode left;
AVLNode right;
int height;
}
private static int height( AVLNode t ) {
return t =s= null ? –1 : t. height;
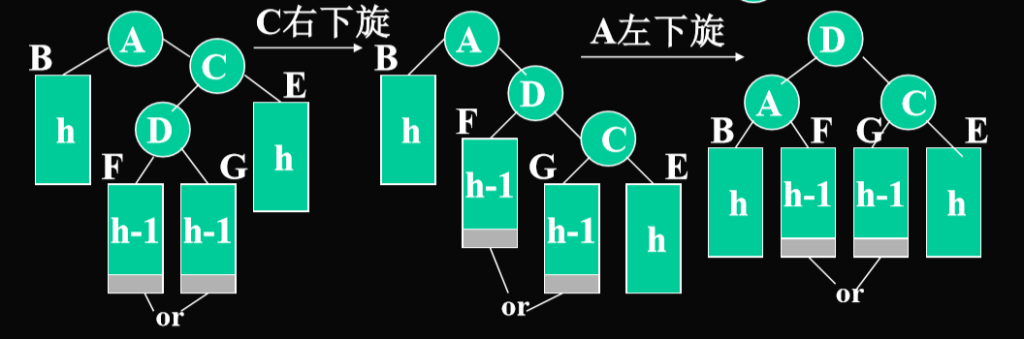
}AVL树的插入操作:
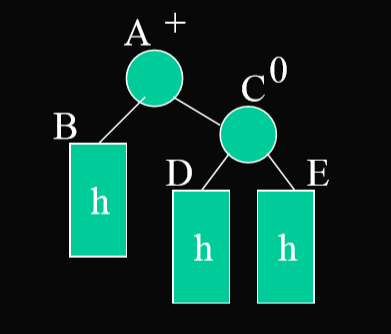
- 简单来看,每一个子树都可以被看为如上的图
- 算法流程:是递归从下向上进行旋转处理,先看子树
插入C的右子树E(外侧结点)
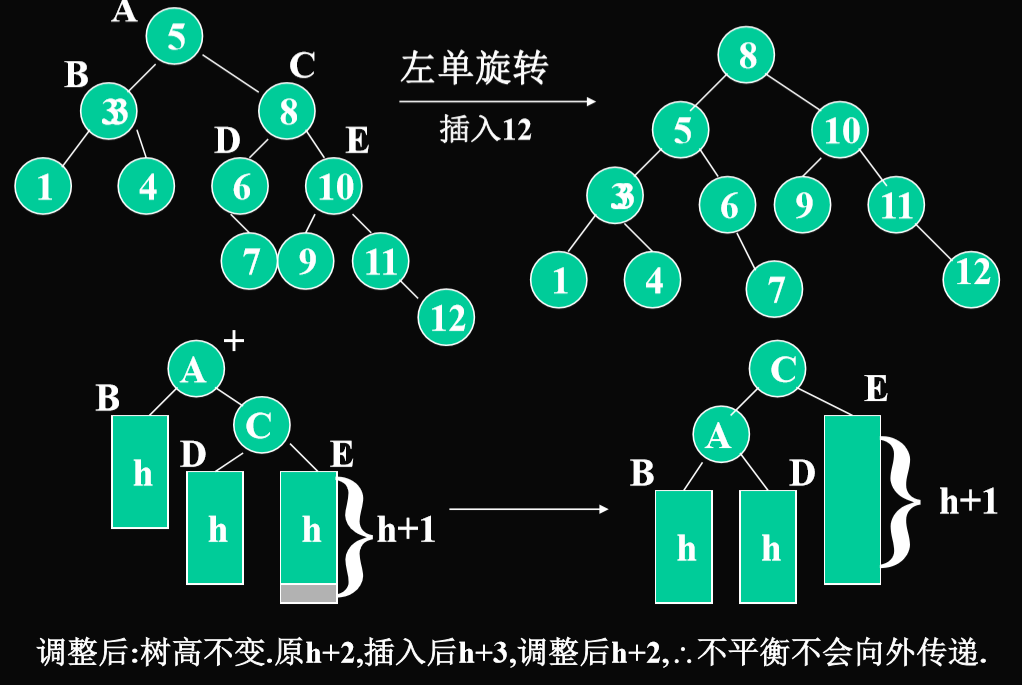
注意左单旋转的方式:C树原本的左子树迁移成原来C的父节点A的右子树
插入C的左子树D(内侧结点)
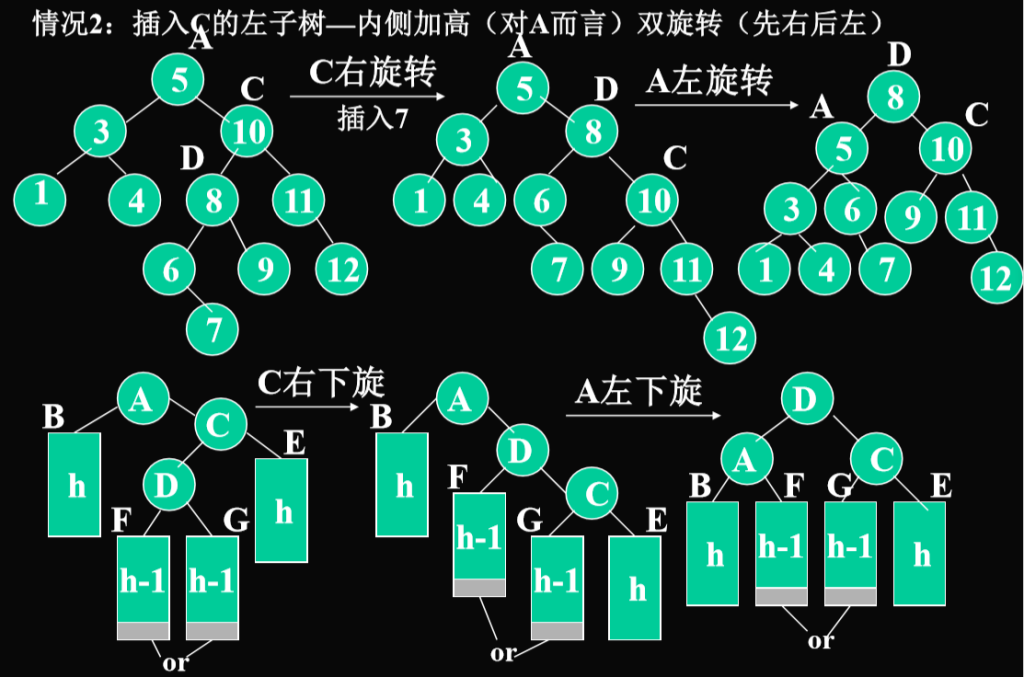
插入其他地方,树不需要转
- 一直到5的时候,树的平衡性才受到影响
- 插入后,树的平衡性没有被破坏显然不用旋转
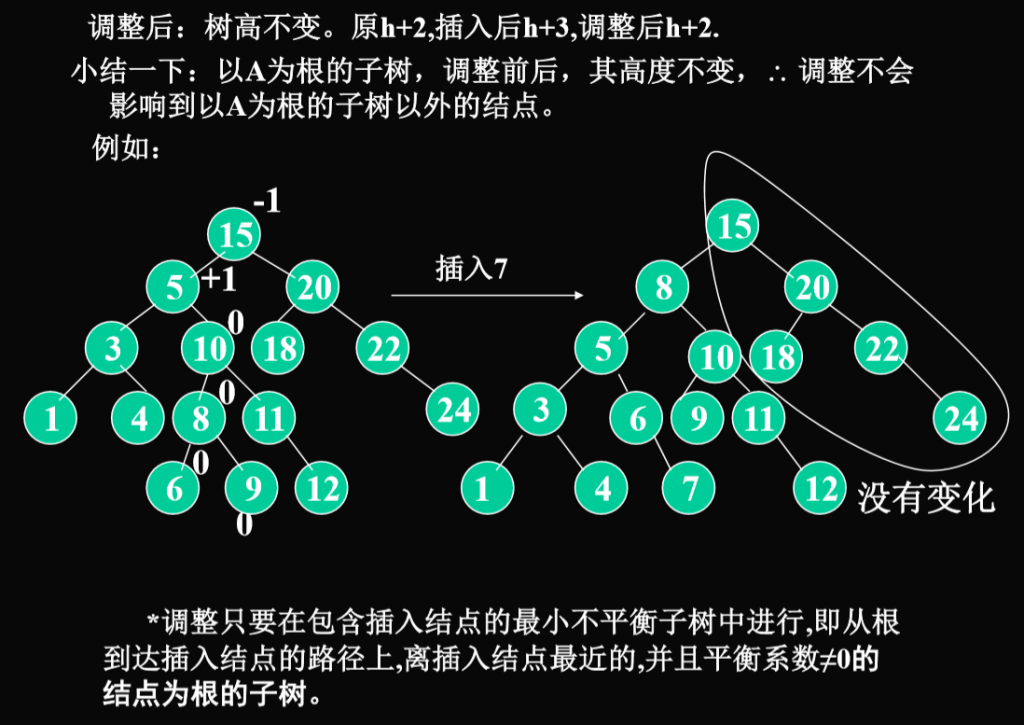
- 调整只要在包含插入结点的最小不平衡子树中进行,即从到达插入结点的路径上,离插入结点最近的,并且平衡系数!=0的结点为根的子树.
总结:
- 算法思想:插入一个新结点后,需要从插入位置沿通向根的路径回溯,检查各结点左右子树的高度差,如果发现某点高度不平衡则停止回溯。
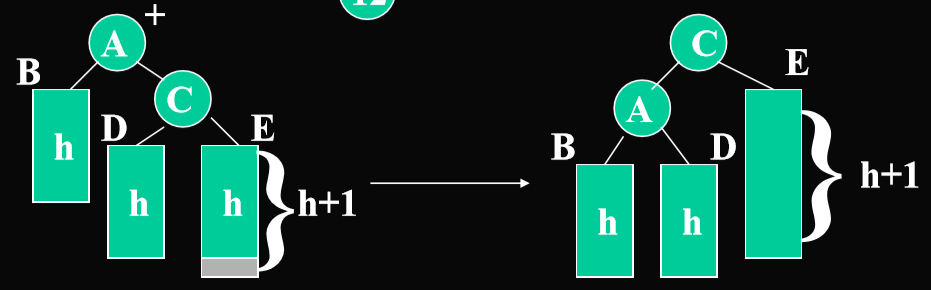
- 先确定节点是在外侧还是内侧,决定是单旋还是双旋
- 单旋转:外侧—从不平衡结点沿刚才回溯的路径取直接下两层如果三个结点处于一直线A,C,E
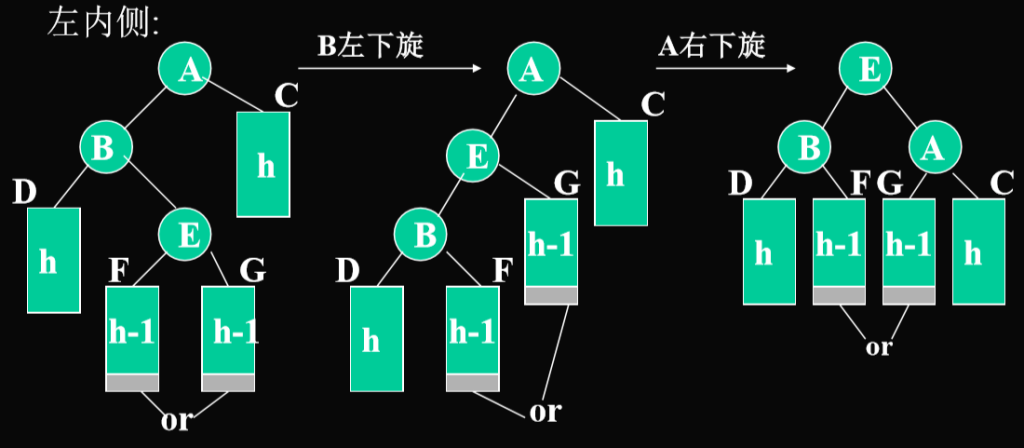
- 双旋转:内侧—从不平衡结点沿刚才回溯的路径取直接下两层如果三个结点处于一折线A,C,D
- 以上以右外侧,右内侧为例,左外侧,左内侧是对称的。与前面对称的情况:左外侧,左内侧 左外侧
右下:

左下
左内
右内
- 首先要找到正确的位置进行插入
- 找到有可能发生不平衡的最小不平衡子树
- 判别插入在不平衡子树的外侧还是内侧
- 根据3的判别结果,再进行单旋还是双旋
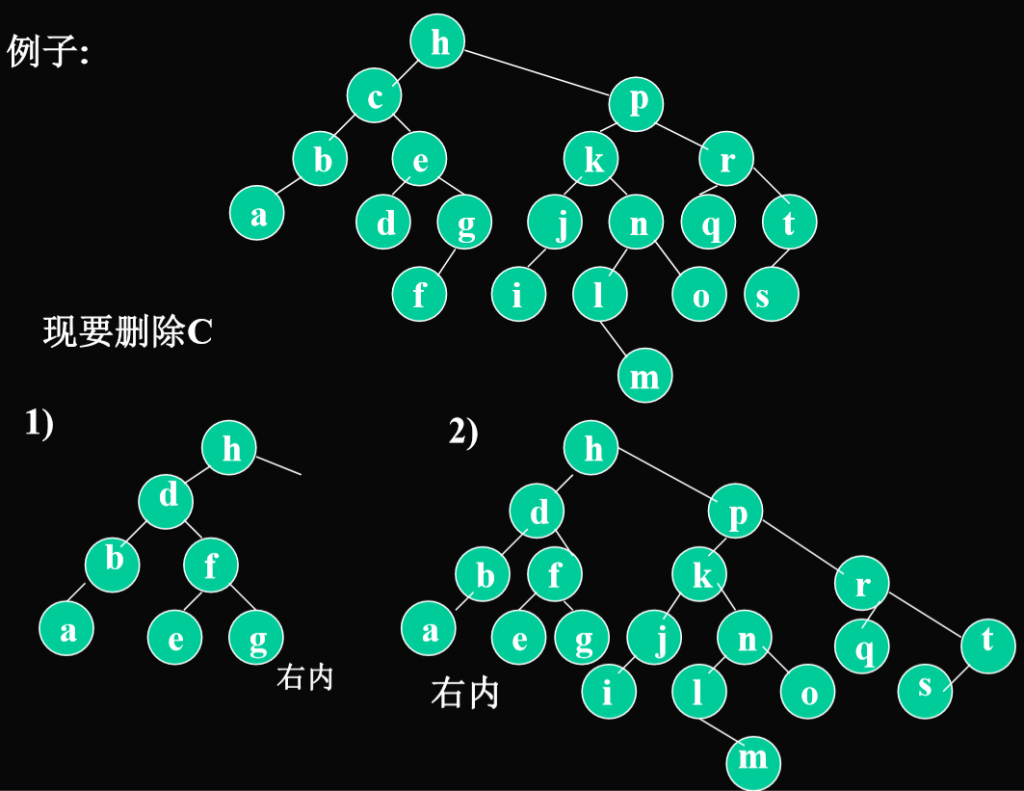
AVL树的删除:

举例:

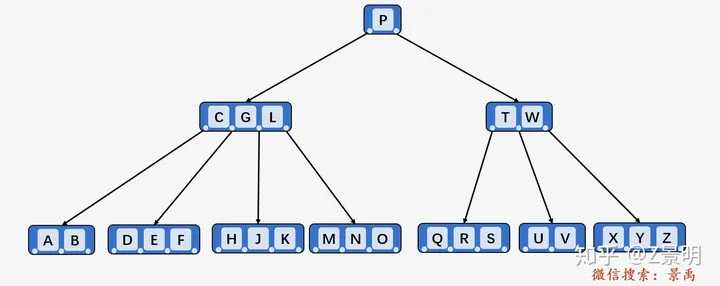
B树(m叉搜索树)
搜索树可能为空。如果是一个非空的树,则为满足以下属性的树:
1.在相应的扩展搜索树(用外部节点替换零指针获得)中,每个内部节点最多有m个子节点,在1和m-1元素之间。
2.每个具有p元素的节点正好有p+1子节点。
c0,c1,……,cp be the p+1 children of the node 假设任何节点都有p个元素,那么C0 – Cp是他们对应的p+1个子元素。
1)每个结点最多有m-1个关键字。
2)根结点最少可以只有1个关键字。
3)非根结点至少有Math.ceil(m/2)-1个关键字
4)每个结点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
操作:
插入:(第一种是m路搜索树的插入)
如果一层没有满,就在同一级进行插入。(针对的是m叉的情况)
如果这一层已经满了,那么在下一层进行插入。
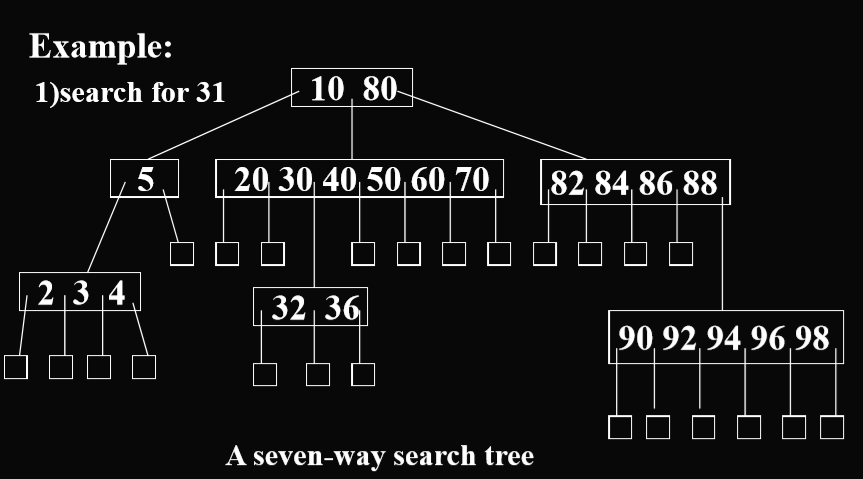
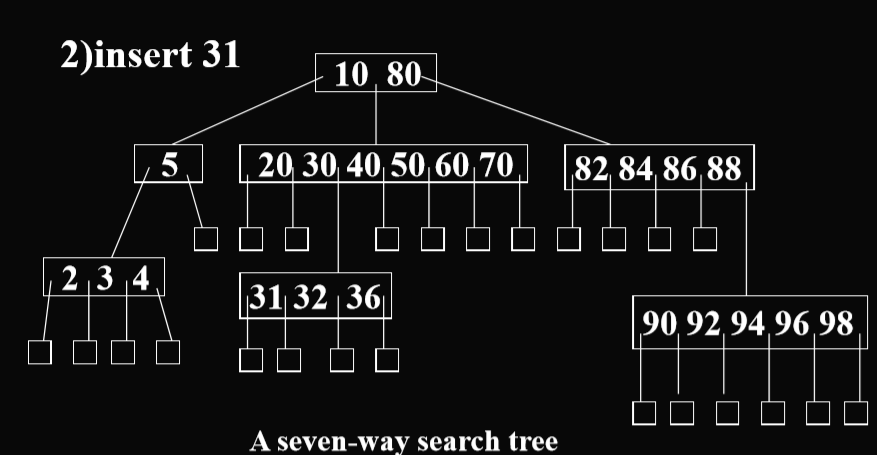
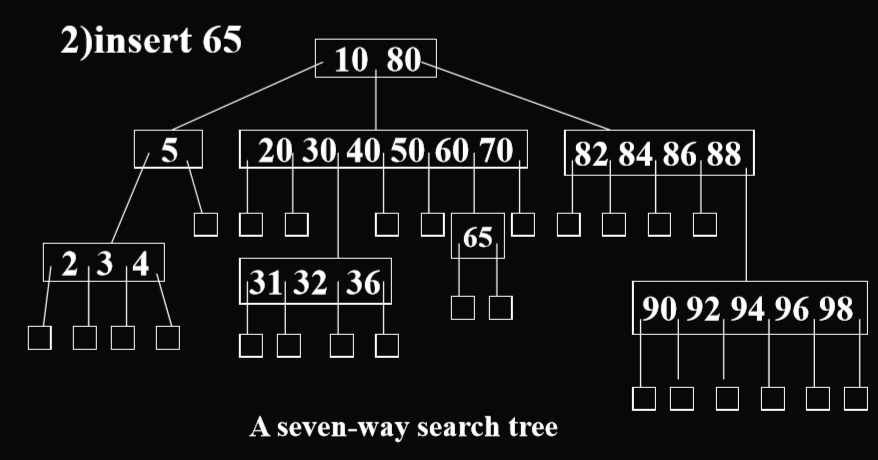
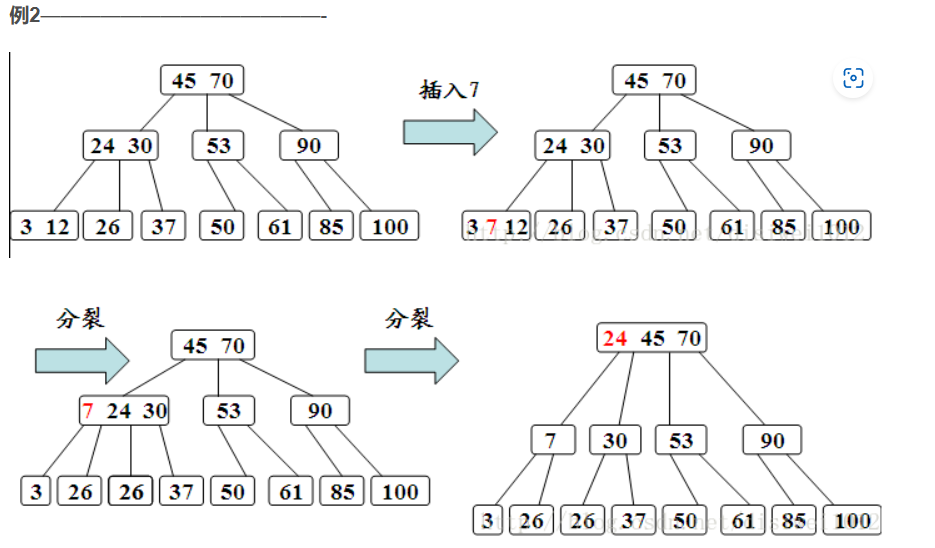
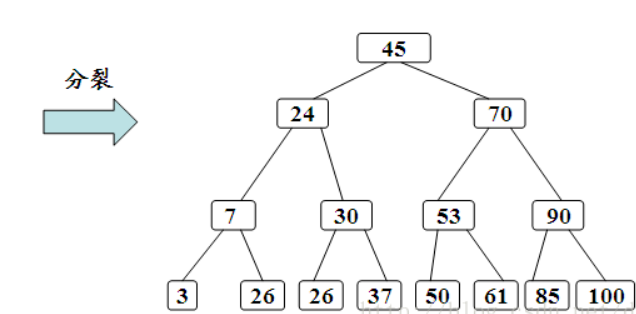
或者更加严谨的是使用分裂法(下图部分数据有误自行识别)
删除操作:
- 删除元素不会影响树的叉数,物理层次影响叉数。
- 类型一:同一层还有节点,直接删除没有影响
- 类型二:本层删除后没有节点,所以需要把底下能合适的最大(最小)的进行提升
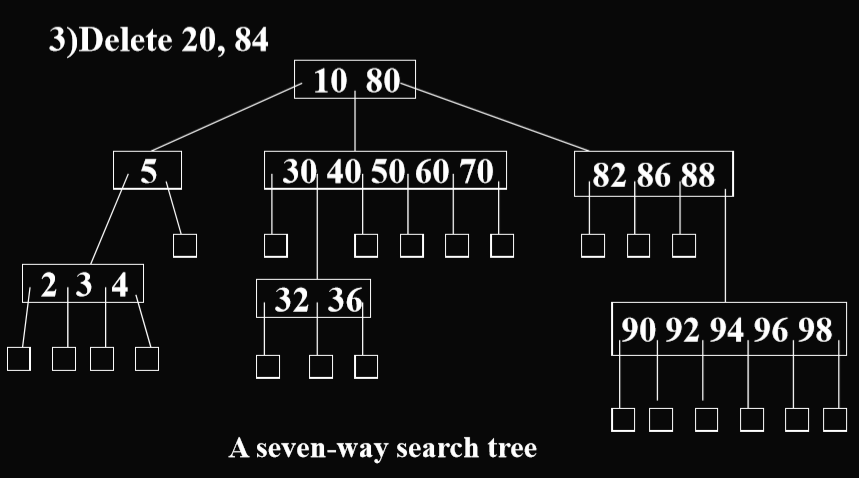
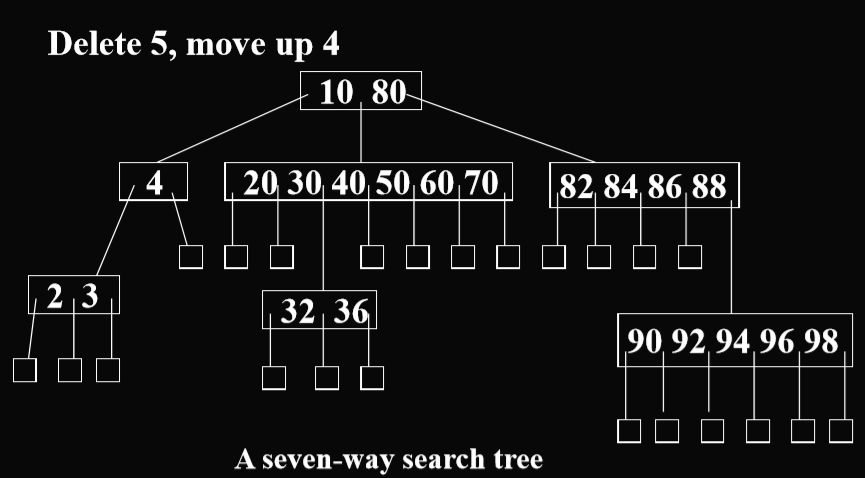
the height of a m-way search tree with n elements is between logm(n+1) and n
m叉搜索树和B树的区别:
- 根节点至少有两个孩子
- 除了根节点以外,所有内部节点至少有[m/2]个孩子
- 所有外部节点位于同一层上,叶节点不包含任何关键字信息
- 每个节点至多有m个孩子
- 有k个孩子的非叶节点恰好包含k-1个关键字

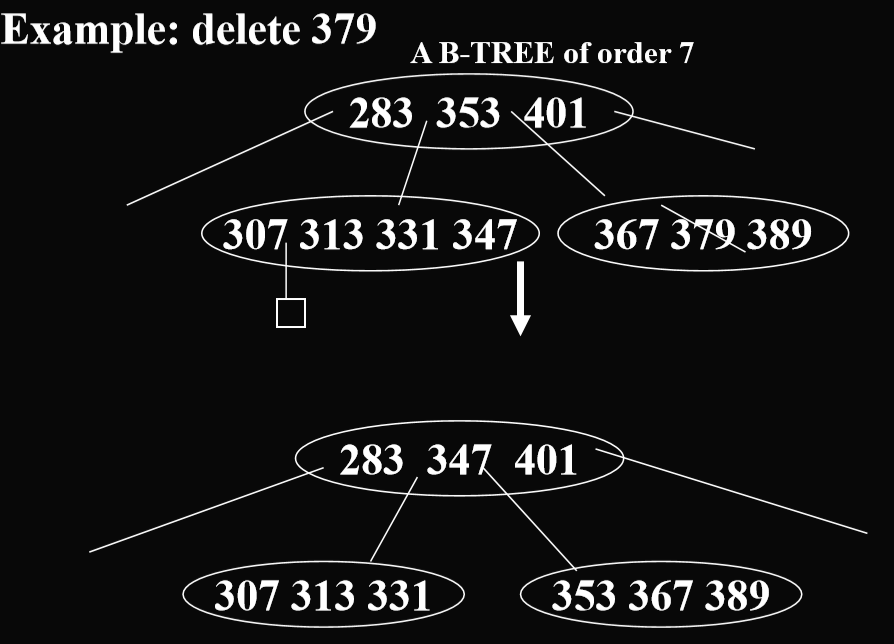
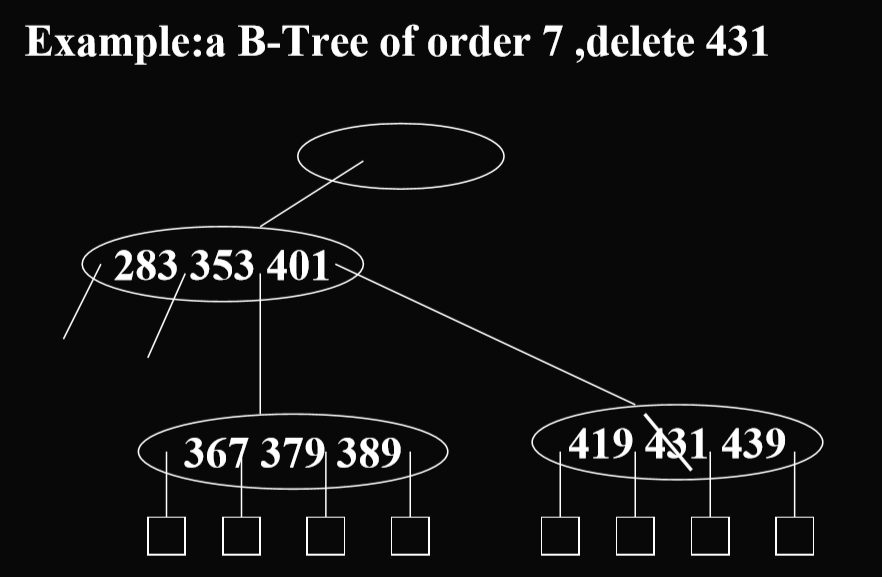
删除操作:
- case1:The element to be deleted is in a node whose children are external nodes(i.e.the element is in a leaf)(将要被删除的元素的关键码的子节点是外部结点[小正方形])
- 如果有超过(m/2)(向上取整)个关键码,直接删除
- 如果关键码个数不足(m/2)(向上取整)个,那么向邻居借关键码,如果够借,那么进行调整。如果不够借,那么合并邻居与此节点(还要拉下来一个上级节点的关键码),这样子也可能会导致上级节点的关键码不足,如果根节点合并,则其高度被减少1。
- case2: The element is to be deleted from a nonleaf. (要被删除的结点是一个非叶节点)
- 删除这个节点
- 把这个节点替换成右子树中的最小关键码(或者左子树中的最大关键码)
- 因为相当于删除了右子树的最小关键码(或者左子树中的最大关键码),所以重复删除叶结点关键码的操作。
优先队列(堆)
在最小优先级队列中,当需要删除一个元素的时候,我们找到优先级最小的元素来删除
最大堆是一个完全二叉树,由于可以完成优先队列所需要的优先出,所以一般用堆的结构来表示优先队列,即使用完全二叉树表示
template<class T>class MaxHeap
{
public:
MaxHeap(int MaxHeapSize=10);
~MaxHeap(){delete[]heap;}
int size()const{return CurrentSize;}
T Max(){
if (CurrentSize==0) throw OutOfBounds();
return heap[1];
}
MaxHeap<T>&insert(const T&x);
MaxHeap<T>& DeleteMax(T& x);
void initialize(T a[], int size, int ArraySize);
private:
int CurrentSize, MaxSize;
T * heap;
}最大堆的构造(同时也是插入操作)
template<class T>MaxHeap<T>& MaxHeap<T>:: Insert(const T& x){
if(CurrentSize= =MaxSize) throw NoMem();
int i=++CurrentSize;
while(i!=1&&x>heap[i/2]){
//0不使用
heap[i]=heap[i/2];
//不必每次都进行完全交换
i/=2;
}
heap[i]=x;
return *this;
}删除操作:
一般采用与最后一位做交换之后直接删除,然后对这个小的节点做向下调整(在该结点的儿子中,找一个最大的,与该结点交换,重复此过程直到底层。)
void down(int x) {
while (x * 2 <= n) {
t = x * 2;
if (t + 1 <= n && h[t + 1] > h[t]) t++;
if (h[t] <= h[x]) break;
std::swap(h[x], h[t]);
x = t;
}
}void build_heap_2() {
for (i = n; i >= 1; i--) down(i);
}堆排序:
初始化一个n个元素的最大堆,每次我们删除最大的元素,调整堆的时间复杂度为O(log2n)
例子:{21,25,49,25*,16,08}
并查集(Disjoint set)
假设我们有一个n个元素组成的集合U = {1,2,…,n},一个有r个关系的集合R.当切仅当以下条件成立的时候,R才是一个等价类
- Reflexive x ≡ x.(自反性)
- Symmetric x ≡ y,y ≡ x(对称性)
- Transitive x ≡ y and y ≡ z,then x ≡ z(传递性)
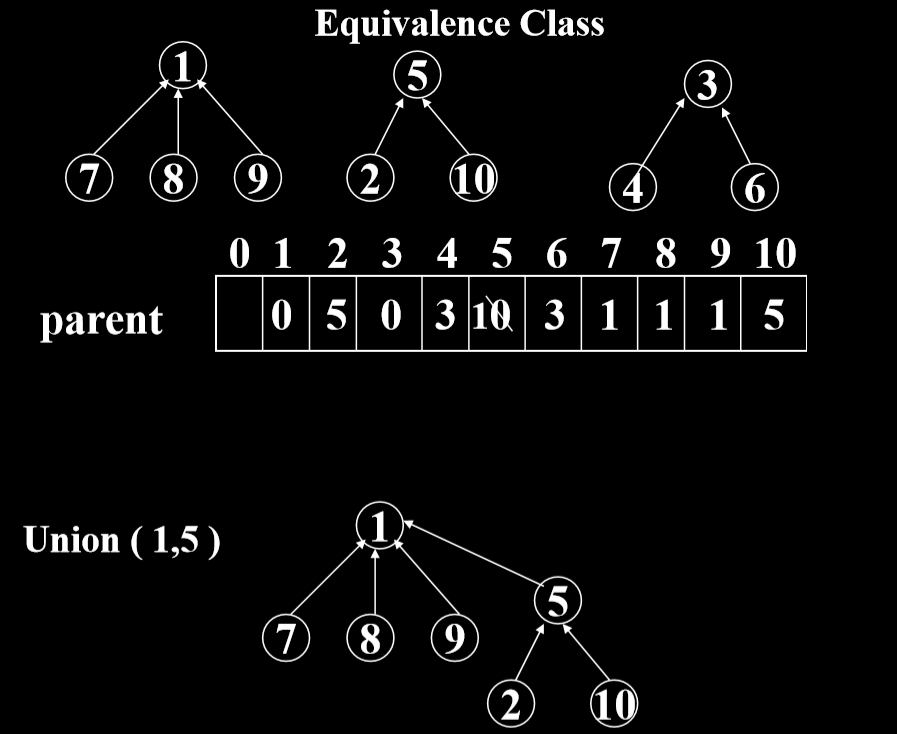
并查集的物理实现:森林
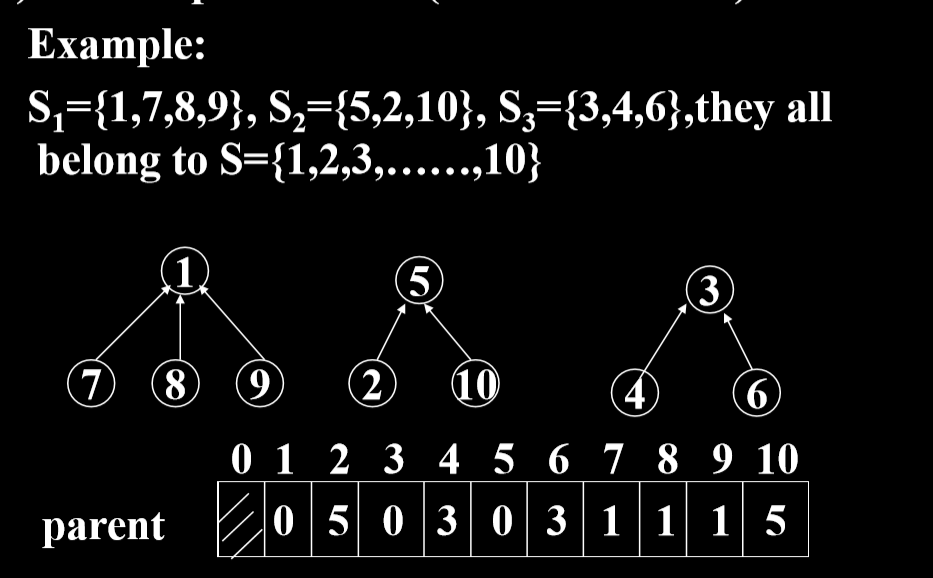
- parent数组中存储的值为0的时候,这个结点表示为根结点
- 所以这个更快速的支持从下向上查询
//simple tree solution to union-find problem
//使用简单的树结构解决并集的查找问题
void Initialize(int n){
parent=new int[n+1];
for(int e=1;e<=n;e++) parent[e]=0;
}
int Find(int e) {
//向上找到其根结点
while(parent[e]) e=parent[e];
return e;
}
void Union(int i, int j) {
//合并两个结点
parent[j]=i;
} public class DisjSets {
public DisjSets( int numElements )
public void union( int root1, int root2 )
public int find( int x ) private int [] s;
}
//并查集的构造方法
public DisjSets( int numElements ) {
s = new int [numElements];
for( int i = 0; i < s.length; i++ )
s[i] = -1; //一个根结点
}
//并查集的合并
public void union( int root1, int root2 ) {
s[root2] = root1;
}
//并查集的查找,使用递归完成
public int find( int x ) {
if( s[x] < 0 )
return x;
else
return find( s[x] );
}有关性能提升:
- 为了实现我们新建一个bool类型数组来记录是否是根节点。
- Besides the parent field, each node has a boolean field root .The root field is true iff the node is presently a root node.The parent field of each root node is used to keep a count of the total number of nodes in the tree.(除了父字段外,每个节点都有一个布尔字段根。如果当前节点是根节点,则根字段为真。每个根节点的父字段用于统计树中的节点总数。)
- 也就是单独使用了一个布尔数组来实现是否为根。(根节点存大小)
void Initialize(int n) {
root=new bool[n+1];
parent=new int[n+1];
for(int e=1;e<=n;e++) {
parent[e]=1;
root[e]=true;
}
}
int Find(int e) {
while(!root[e])
e=parent[e];
return e;
}
void Union(int i, int j) {
if(parent[i]<parent[j])
//i becomes subtree of j
{
parent[j]=parent[j]+parent[i];
root[i]=false;
parent[i]=j;
} else {
parent[i]=parent[i]+parent[j];
root[j]=false;
parent[j]=i;
}
}也可以采用“负数计数”直接标记根节点,省去bool数组
其他方式——路径压缩,直接连接到根节点
图(graph)
(暂时不考虑自环和多重边)
- 对于无向图只有度数,而对于有向图不仅仅有入度,还有出度。
- degree dv of vertex v, TD(v): is the number of edges incident on vertex v. In a directed graph :(顶点v的度数为dv,TD(V)是顶点v的度数,在有向图中)
- in-degree of vertex v is the number of edges incident to v, ID(v).(顶点v的入度是指向顶点v的边的个数)
- out-degree of vertex v is the number of edges incident from the v, OD(v). (顶点v的出度从v出发的边的个数)
- 性质:(度数)TD(v)=ID(v)+OD(v)

所有的度数加起来是边的个数的两倍
在图 G=(V,E)中,如果每j的边(ij,ij+1)在E中,1<= j< k,则顶点序列P=i1,i2,…,ik是i1到ik的路径。
简单路径 : 路径除了第一个和最后一个顶点中没有出现相同的顶点
图的总抽象:
AbstractDataType Graph {
//instances 实例
a set V of vertices and a set E of edges 顶点集合V 和 边集E
//operations 操作
Create(n):create an undirected graph with n vertices and no edges 创建一个n个顶点没有边的无向图
Exist(i,j): return true if edge(i,j)exists; false otherwise 当且仅当存在边i、j的时候返回true
Edges():return the number of edges in the graph 返回图的边的个数
Vertices():return the number of vertices in the graph 返回图的顶点个数
Add(i,j): add the edge(i,j) to the graph 将i、j边添加到图中
Delete(i,j):delete the edge (i,j) 删除边i、j
Degree(i): return the degree of vertex i 返回顶点i的度数
InDegree(i): synonym for degree 和度数相同
OutDegree(i): synonym for degree 和度数相同
}图的视线与表示:
1。邻接矩阵
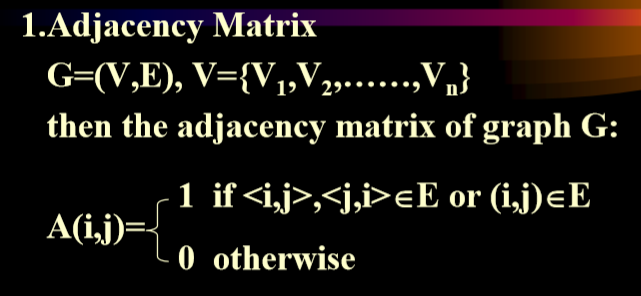
无向图的每个顶点的度数等于矩阵中每一行的和
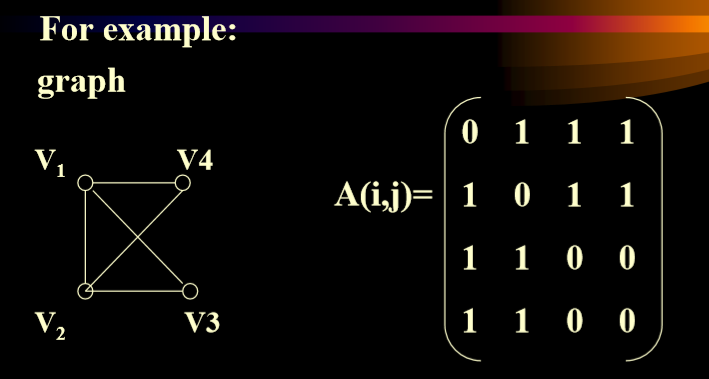
- 有向图的邻接矩阵
- 出度对行求和
- 入度对列求和
其他需要的结构
- 一个记录各顶点信息的表
- 一个当前的边数
const int MaxNumEdges = 50// 最大边数
const int MaxNumVertices = 10//最大顶点数
template<class NameType, class DistType> class Graph{
private:
SeqList<NameType> VerticesList(MaxNumVertices) //顶点表
DistType Edge [MaxNumVertices] [MaxNumVertices] //邻接矩阵,一定是方阵
int CurrentEdges;//当前边数
int FindVertex (Seqlist <NameType> &L; const NameType &Vertex)
{return L.Find(Vertex);}
int GetVertexPos (const NameTyoe &Vertex)
{return FindVertex(VerticesList);}// 给出了顶点Vertex在图中的位置
public:
Graph (const int sz=MaxNumEdges);
int GraphEmpty() const{return VerticesList.IsEmpty();}
int GraphFull() const{return VerticesList.IsFull() || CurrentEdges= =MaxNumEdges;}
int NumberofVertices(){return VerticesList.last;}
int NumberofEdges() {return CurrentEdges;}
NameType Getvalue(const int i) {return i>=0 && i<VerticesList.last ? VerticesList.data[i] : NULL;}
DistType Getweight (const int v1,const int v2);
int GetFirstNeighbor(const int v);
int GetNextNeighbor(const int v1,const int v2);
void InsertVertex(const NameType & Vertex);
void InsertEdge(const int v1,const int v2, DistType weight);
void removeVertex(const int v);
void removeEdge(cosnt int v1,const int v2);
} 求顶点V的第一个邻接顶点的位置:
template<class NameType, class DistType> int Graph<NameType, DistType>::GetFirstNeighbor(int v) {
if (v!=-1) {
for(int col=0; col<CurrentVertices; col++)
if (Edge[v][col]>0 && Edge[v][col]<max)
return col;
}
return -1;
}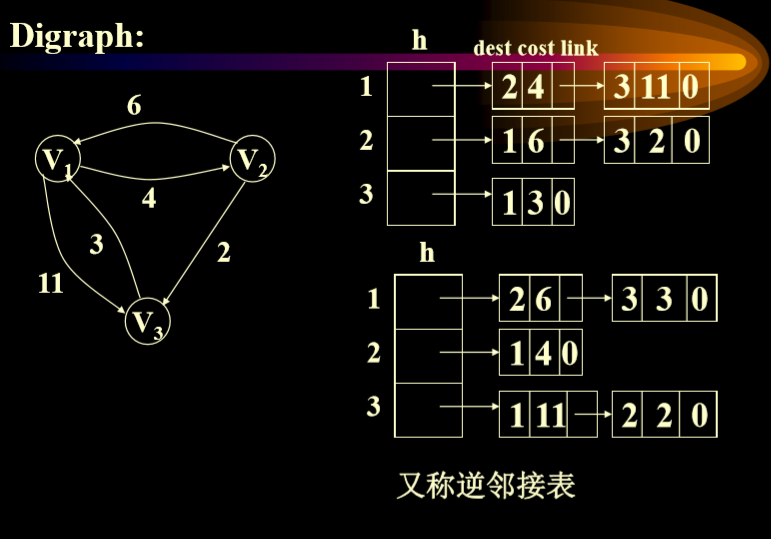
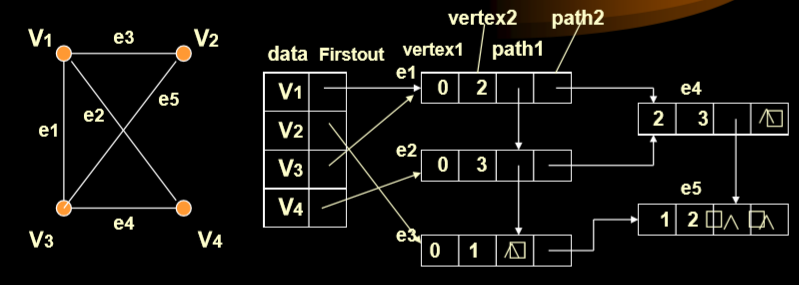
邻接多重表
- 在无向图中, 如果边数为m, 则在邻接表表示中需2m个单位来存储. 为了克服这一缺点, 采用邻接多重表, 每条边用一个结点表示.
- 其中的两个结点号就是边的两个点。
- path1指向的就是同样始点(vertex1),顺序终点的结果。
- path2执行的是以vertex2为始点顺序向下的。
DFS
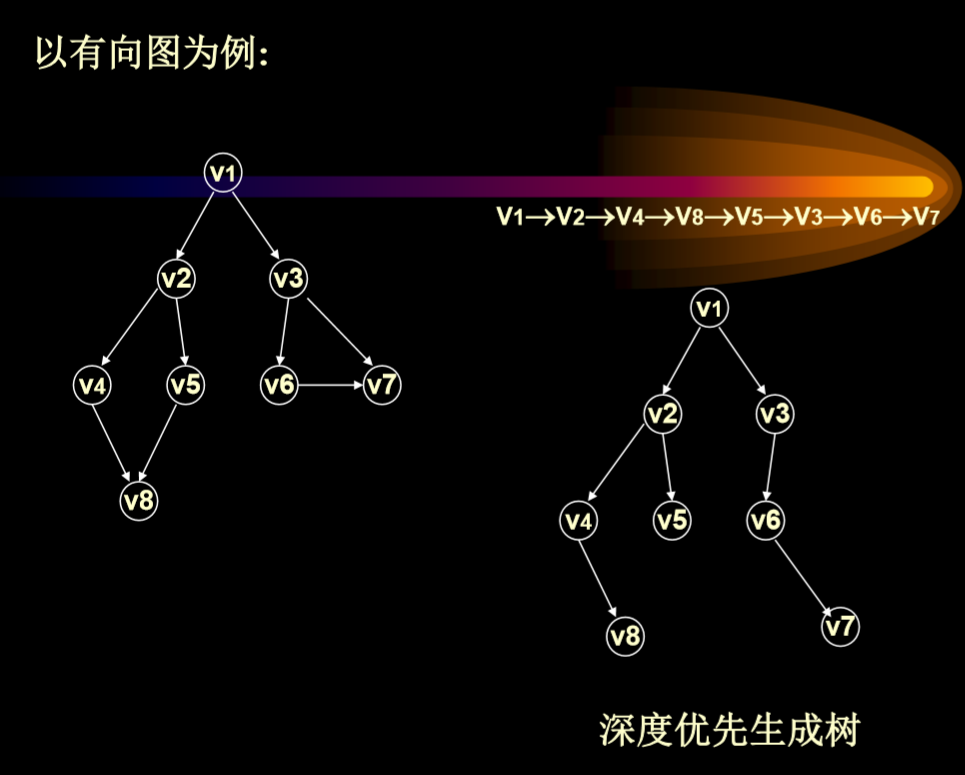
- 递归方法实现 算法中用一个辅助数组visited[]:
- 0:未访问
- 1:访问过了
- 我们假设图为连通图
//利用的是邻接矩阵来表示的图
//主过程:
template<NameType,DistType> void Graph<NameType,DistType>::DFS( ) {
int *visited=new int[NumVertices];
for ( int i=0; i<NumVertices; i++)
visited[i]=0;
DFS(0,visited);//从顶点0开始深度优先搜索
delete[] visited;//释放visited的空间
}
//子过程
template<NameType,DistType> void Graph<NameType,DistType>::DFS(int v, visited[]) {
cout<<GetValue(v)<<"";
visited[v]=1;
int w = GetFirstNeighbor(v);
while (w!=-1) {
if(!visited[w])
DFS(w,visited);//最坏情况,就是每一次w都没有被访问过
w = GetNextNeighbor(v,w);
}
//无论如何,最坏情况下访问次数,也就只能是图中所有边的个数。
//也就是对邻接矩阵所有边会被扫一遍
}BFS
同样需要一个visited来存储是否访问过,还需要一个队列,记正在访问的这一层和上一层的顶点. 算法显然是非递归的.
template<NameType,DistType> void Graph<NameType,DistType>::BFS(int v) {
//这个算法使用了队列
int* visited=new int[NumVertices];
for (int i=0; i<NumVertices; i++)
visited[i]=0;
cout << GetValue(v) << "";
//访问结点
visited[v]=1;
//使用队列来存储顶点
queue<int> q;
q.EnQueue(v);
while(!q.IsEmpty()) {
v= q.DeQueue();
int w= GetFirstNeighbor(v);
while (w!=-1) {
if(!visited[w]) {
cout<<GetValue(w)<<"";
visited[w]=1;
q.EnQueue(w);
}
w= GetNextNeighbor(v,w);
//访问完成一层的结点
}
}
delete[] visited;
}求非连通图的遍历,只需要在深度优先搜索处,加上以所有点为起点就可以遍历。(本来只用DFS(0,visited))
最小生成树
- 设G =(V,E)是一个连通的无向图(或是强连通有向图) 从图G中的任一顶点出发作遍历图的操作,把遍历走过的边的集合记为TE(G),显然 G‘=(V,TE)是G之子图, G‘被称为G的生成树(spanning tree),也称为一个连通图.
- n个结点的生成树有n-1条边。
- 生成树的代价(cost):TE(G)上诸边的代价之和
- 生成树不唯一

1.贪心法求解最小生成树:Prim和Kruskal两种方式
- Grandy策略:设:连通网络N={V,E}, V中有n个顶点。
- 先构造 n 个顶点,0 条边的森林 F ={T0,T1,……,Tn-1}
- 每次向 F 中加入一条边。该边是一端在 F 的某棵树Ti上而另一端不在Ti上的所有边中具有最小权值的边。 这样使F中两棵树合并为一棵,树的棵数 – 1
- 重复上述操作n-1次
- 去掉所有边,每次加入的边是当前最小的边,并且保证这个边不是回边。
Kruskal算法(对边进行排序,然后生成)
把无向图的所有边排序
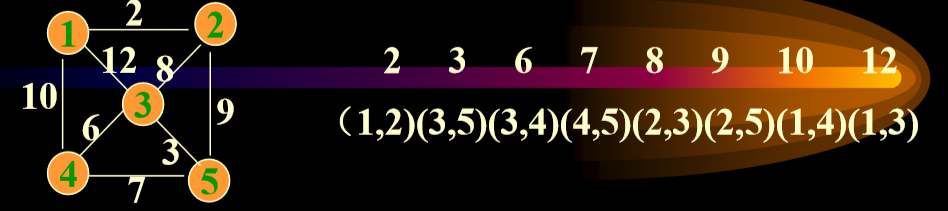
一开始的最小生成树为

在E中选一条代价最小的边(u,v)加入T,一定要满足(u,v) 不和TE中已有的边构成回路
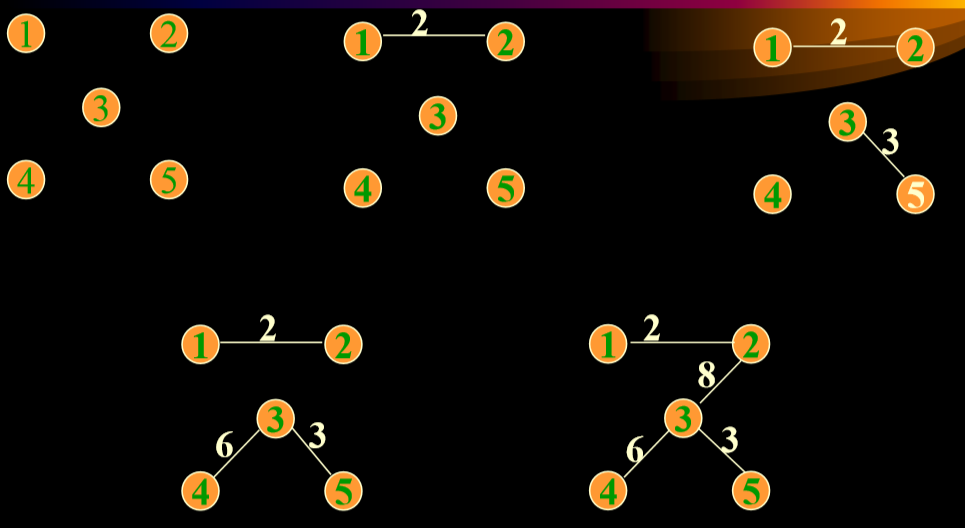
void Graph<string,float>::Kruskal(MinSpanTree&T) {
//结果赋值给T
MSTEdgeNode e;
MinHeap<MSTEdgeNode>H(currentEdges);
int NumVertices=VerticesList.Last , u , v ;
Ufsets F(NumVertices);//建立n个单元素的连通分量
for(u=0;u<NumVertices;u++)
for (v=u+1;v<NumVertices;v++)
if(Edge[u][v]!=MAXINT) {
e.tail=u;
e.head=v;
e.cost=Edge[u][v];
H.insert(e);
//完成堆的初始化,将每一条边插入到优先级队列中去
}
int count=1;//生成树边计数
while(count<NumVertices) {
H.RemoveMin(e);
u=F.Find(e.tail);//找到并查集的树根
v=F.Find(e.head);//找到并查集的树根
if(u!=v){
//并查集做回边检测,在同一个并查集中就是一个回边,不然就不是
F.union(u,v);
T.Insert(e);
count++;//计数已经查找出来的个数
}
//最坏的情况时所有的边都被访问一次,比如目标边是最后一条边。
}
}Prim算法
- 设:原图的顶点集合V(有n个)生成树的顶点集合U(最后也有n个),一开始为空TE集合为{}
- 步骤:
- U={1}任何起始顶点,TE={}
- 每次生成(选择)一条边。这条边是所有边(u,v) 中代价(权)最小的边, u∈U,v∈V-U TE=TE+[(u,v)]; U=U+[v]
- 当U≠V,返回上面一个步骤
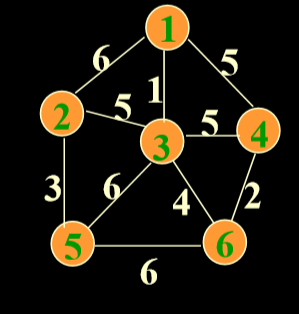
最短路径
- 设G=(V,E)是一个带权图(有向,无向),如果从顶点v到顶点w的一条路径为(v,v1,v2,…,w),其路径长度不大于从v到w的所有其它路径的长度,则该路径为从 v 到 w 的最短路径。
- 背景:在交通网络中,求各城镇间的最短路径。
- 三种算法:
- 边上权值为非负情况的从一个结点到其它各结点的最短路径 (单源最短路径)(Dijkstra算法)
- 边上权值为任意值的单源最短路径
- 边上权值为非负情况的所有顶点之间的最短路径
含非负权值的单源最短路径
Dijkstra

贝尔曼——福特改进算法
可以检测负边权,每次固定松弛操作n-1次
floyed算法
是用来求任意两个结点之间的最短路的。
复杂度比较高,但是常数小,容易实现(只有三个 for)。
适用于任何图,不管有向无向,边权正负,但是最短路必须存在。(不能有个负环)
活动网络

拓扑算法思想
- 从图中选择一个入度为0的结点输出之。(如果一个图中,同时存在多个入度为0的结点,则随便输出任意一个结点)
- 从图中删掉此结点及其所有的出边。
- 反复执行以上步骤
- 直到所有结点都输出了,则算法结束
- 如果图中还有结点,但入度不为0,则说明有环路
AOE网络
- 用边表示活动的网络(AOE网络, Activity On Edge Network)又称为事件顶点网络
- 顶点:
- 表示事件(event) 事件——状态。表示它的入边代表的活动已完成,它的出边 代表的活动可以开始,如下图v0表示整个工程开始,v4表示a4,a5活动已完成a7,a8活动可开始。
- 表示事件(event) 事件——状态。表示它的入边代表的活动已完成,它的出边 代表的活动可以开始,如下图v0表示整个工程开始,v4表示a4,a5活动已完成a7,a8活动可开始。
- 有向边:
- 表示活动。 边上的权——表示完成一项活动需要的时间
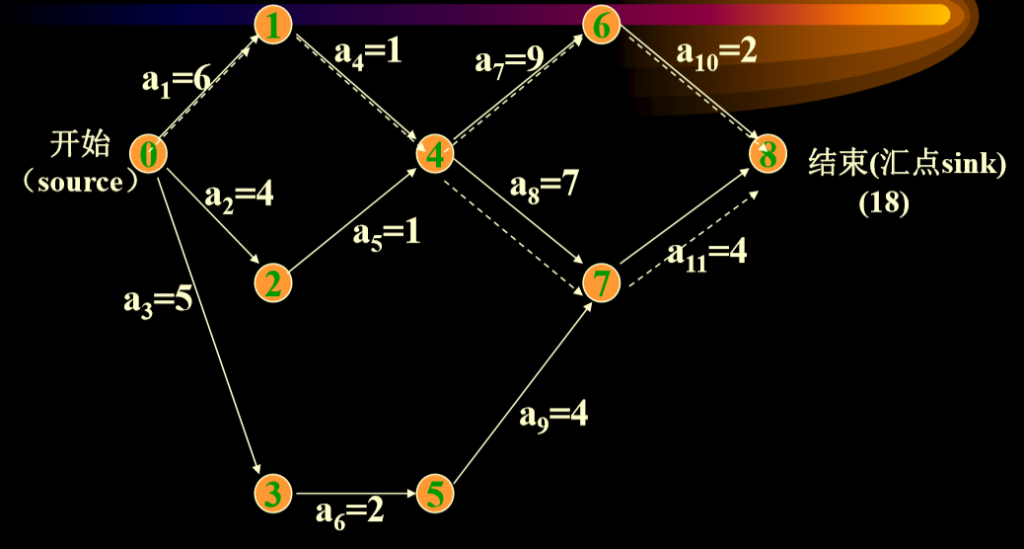

关键路径
- 目的: 利用事件顶点网络,研究完成整个工程需要多少时间 加快那些活动的速度后,可使整个工程提前完成。
- 关键路径:具有从开始顶点(源点)->完成顶点(汇点)的 最长的路径
- 对于活动:
- e[k]-表示活动ak=<Vi,Vj>的可能的最早开始时间。 即等于事件Vi的可能最早发生时间。 e[k]=Ve[i]
- l[k]-表示活动ak= <Vi,Vj> 的允许的最迟开始时间 l[k]=Vl[j]-dur(<i,j>);
- l[k]-e[k]-表示活动ak的最早可能开始时间和最迟允许开始时间的时间余量。也称为松弛时间。 (slack time)
- l[k]==e[k]-表示活动ak是没有时间余量的关键活动
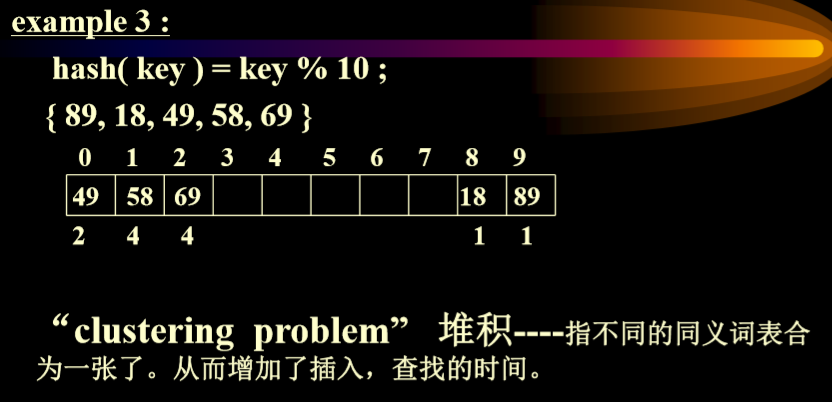
Hashing(哈希)
key:如何解决散列表冲突问题
1.3.1. 解决冲突方案(1):linear Probing(线性探测法)
If hash(key)= d and the bucket is already occupied then we will examine successive buckets d+1, d+2,……m-1, 0, 1, 2, ……d-1, in the array(如何key的哈希值是d,并且d对应的位置已经被占据,然后我们会按照线性顺序向后成环形查找)
线性表示法的弊端:堆积问题
1.3.2. 解决冲突方法(2):二次探测法(Quadratic probing)
放置hash值相同的情况下导致严重的堆积情况。

1.3.3. 解决冲突方法(3):双散列哈希(Double Hashing)
If hash1(k)= d and the bucket is already occupied then we will counting hash2(k) = c, examine successive buckets d+c, d+2c, d+3c……,in the array(如果k的第一哈希值为d,而这个对应的格子已经被占用则我们继续计算k的第二哈希值,然后检查d+c…)

尽量保证表项数>表的70%,也就是意味着如果不满足,就需要进行再散列。
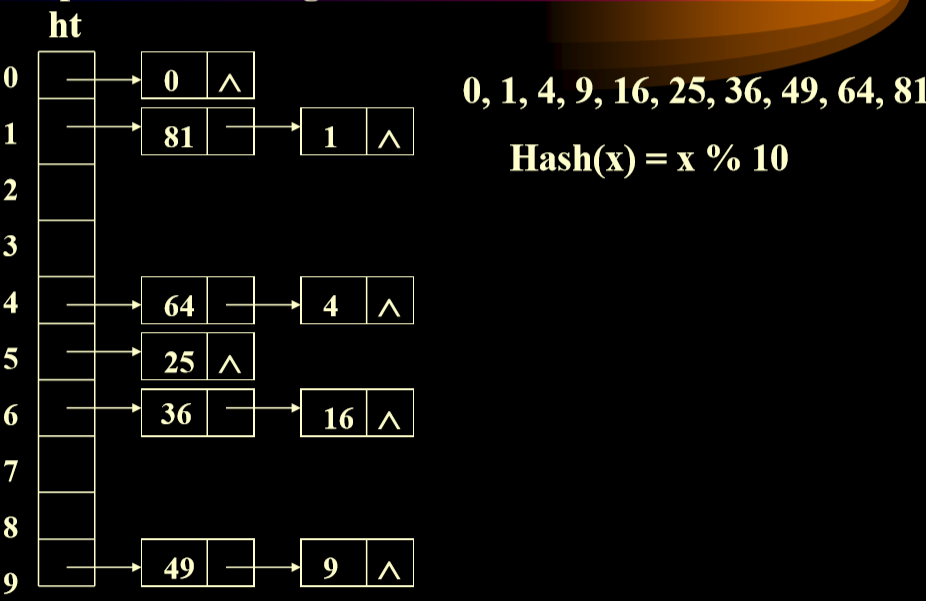
解决冲突方法(4):分离链接法(Separate Chaining)
使用每个位置对应线性表解决这个问题
排序算法
插入排序:
- 比较的时候是从后向前比较的。
- 合并后的插入排序
//Another version of insertion sort
public static void InsertionSort(int []a, int n) {
for(int i=0;i<n;i++){
//insert a[i] into a[0:n-1]
int t=a[i];
int j;
for(j=i-1; j>=0&&t<a[j]; j--)
a[j+1]=a[j];
a[j+1]=t;
//比前面大后推一格
}
}折半插入排序:
//java
public static int binarySearch( Comparable [] a, Comparable x ) {
int low = 0, high = a.length - 1;
while( low <= high ) {
//计算出中点是哪一个
int mid = (low+high) / 2;
//调整两端的值
if( a[mid].compareTo(x) < 0)
low = mid + 1;
else if(a[mid ].compareTo(x) > 0)
high = mid – 1;
else return mid;
}
return "NOT-FOUND";
}(插排中+二分)
希尔排序:
- 又称缩小增量排序(diminishing – increament sort)
- 方法:
- 取一增量(间隔gap < n),按增量分组,对每组使用 直接插入排序或其他方法进行排序。
- 减少增量(分的组减少,但每组记录增多)。直至增量为1,即为一个组时。

public static void shellsort( Comparable [ ] a ) {
for (int gap = a.length/2 ; gap>0 ; gap/=2 )
for (int i = gap; i < a.length; i++) {
//遍历一遍
Comparable tmp = a[i];
int j = i;
for (;j >= gap && tmp.compareTo( a[j-gap] )< 0;j -= gap )
//完成一遍下滤
a[j] = a[j – gap];
a[j] = tmp;
}
}希尔排序算法分析
- 与选择的缩小增量有关,但到目前还不知如何选择最好结果的缩小增量序列。
- 平均比较次数与移动次数大约n1.3左右
交换排序(一类排序方式)
1。冒泡排序
- 每次遍历一次数组,然后仅仅比较相邻的两个数字,最坏的情况时每次只能讲一个数字冒泡上去。
- 然后遍历n次
//java
public static void Bubble( int [ ] a , int n) {
//Bubble largest element in a[0:n-1] to right
for(int i=0; i<n-1; i++)
if(a[i] > a[i+1])
swap(a[i],a[i+1]);
}
public static void BubbleSort( int [ ] a, int n) {
//Sort a[0:n-1] using a bubble sort
for(int i=n ;i>1; i--)
Bubble(a,i);
}2。快速排序
- 在n个对象中,取一个对象(如第一个对象——基准pivot),按该对象的关键码
- 把所有小于等于该关键码的对象分划在它的左边。
- 大于该关键码的对象分划在它的右边。
- 对左边和右边(子序列)分别再用快速排序。
//c++
template <class Type> void QuickSort( datalist <Type>& list, const int left, const int right ) {
if (left<right) {
int pivotpos = partition(list, left, right);
QuickSort(list, left, pivotpos-1);
QuickSort(list, pivotpos+1, right);
}
}
//partition
template <class Type> int partition(datalist<Type> &list, const int low, const int high) {
int i=low,j=high; Element<Type>pivot=list.Vector[low];
while (i != j ) {
while(list.Vector[j].getkey()>pivot.getkey( ) && i<j)
j--;
if (i<j) {
list.Vector[i]=list.Vector[j];
i++;
}
while(list.Vector[i].getkey()<pivot.getkey( ) && i<j)
i++;
if (i<j) {
list.Vector[j]=list.Vector[i];
j--;
}
}
list.Vector[i]=pivot;
return i;
}- 选取pivot(枢纽元)用第一个元素作pivot是不太好的。
- 方法1:随机选取pivot, 但随机数的生成一般是昂贵的。
- 方法2:三数中值分割法(Median-of-Three partitioning) N个数,最好选第(N/2)(向上取整)个最大数,这是最好的中值,但这是很困难的。一般选左端、右端和中心位置上的三个元素的中值作为枢纽元。
- 8, 1, 4, 9, 6, 3, 5, 2, 7, 0 (8, 6, 0)
- 具体实现时:将 8,6,0 先排序,即 0, 1, 4, 9, 6, 3, 5, 2 , 7, 8, 得到中值pivot为 6
- 分割策略:
- 将pivot与最后倒数第二个元素交换,使得pivot离开要被分割的数据段。然后,i 指向第一个元素,j 指向倒数第二个元素。
- 0, 1, 4, 9, 7, 3, 5, 2, 6, 8
- 然后进行分划
- 将pivot与最后倒数第二个元素交换,使得pivot离开要被分割的数据段。然后,i 指向第一个元素,j 指向倒数第二个元素。
- 三数中值分隔法
选择排序
思想:首先在n个记录中选出关键码最小(最大)的 记录,然后与第一个记录(最后第n个记录)交换位置,再在其余的n-1个记录中选关键码 最小(最大)的记录,然后与第二个记录(第n-1个记录)交换位置,直至选择了n-1个记录
//java
public static void SelectionSort(int [] a, int n) {
//sort the n number in a[0:n-1].
//找到大数字放置到后面
for(int size = n; size>1; size--){
//n-1
int j = Max(a,size);
//n-1+n-2+...+1
swap(a[j],a[size-1]);
}
} 锦标赛排序:
- 直接选择排序存在重复做比较的情况,锦标赛 排序克服了这一缺点。
- 具体方法:
- n个对象的关键码两两比较得到(n/2)(向上取整)个 比较的优胜 者(关键码小者)保留下来, 再对这(n/2)(向上取整)个对象再进行关键码的两两比较, ……直至选出一个最小的关键码为止。如果n不是2的K次幂,则让叶结点数补足到满足 2k < n <= 2k个。
- 输出最小关键码。再进行调整:即把叶子结点上,该最小关键码改为最大值后,再进行 由底向上的比较,直至找到一个最小的关键码(即次小关 键码)为止。重复2,直至把关键码排好序。
堆排序:
算法思想
- 第一步,建堆,根据初始输入数据,利用 堆的调整算法FilterDown(),形成初始堆。(形成最大堆)
- 第二步,一系列的对象交换和重新调整堆
//java program
public static void heapsort( Comparable []a) {
for( int i = a.length / 2; i >= 0; i-- )
percDown( a, i, a.length );
for( int i = a.length – 1; i > 0; i-- ) {
swapReferences( a, 0, i );
percDown( a, 0, i);
}
}
private static int leftChild( int i ) {
return 2 * i + 1;
}
private static void percDown( Comparable [ ] a, int i, int n ) {
int child;
Comparable tmp;
for( tmp = a[i];leftChild(i) < n ; i = child ) {
child = leftchild( i );
if( child!=n – 1&& a[child].compareTo( a[ child + 1 ] ) < 0 )
child ++;
if( tmp . compareTo( a[ child ] < 0 )
a[ i ] = a[ child ];
else
break;
}
a[i] = tmp;
}秩排序:
记录排名排序,需要一个额外的排名数组记录
public static void Rank( int [] a, int n, int [] r) {
//Rank the n elements a[0:n-1]
for(int i=0;i<n;i++){
r[i]=0;
}
//首先将全部的数字重置为0
for(int i=1;i<n;i++)
for(int j=0;j<i;j++)
if(a[j]<=a[i])
r[i]++;
else
r[j]++;
//胜者排名不需要向后增加,而败者需要增加次序。
}
public static void Rearrange( int [ ]a, int n, int[ ] r) {
//In-place rearrangement into sorted order
for(int i=0;i<n;i++)
while(r[i]!=i) {
//在数组[n]上的应该是第n+1大的数字
int t=r[i];
swap(a[i],a[t]);
swap(r[i],r[t]);
}
}基数排序:
- 先取个位数,按照个位数来放到十个桶里面。
- 根据先后次序进图桶
- 按照十位数,继续放入桶中,根据个位排序结果
- 重复上述操作,直到最高位。
- 原理:每次让这一位的从前往后排序。

归并排序:
归并:两个(多个)有序的文件组合成一个有序文件 方法:每次取出两个序列中的小的元素输出之;当一序列完,则输出另一序列的剩余部分

//java
public static void mergeSort( Comparable [ ] a ) {
Comparable [ ] tmpArray = new Comparable[a.length];
mergeSort( a, tmpArray, 0, a.length – 1 );
}
private static void mergeSort( Comparable [ ] a, Comparable [] tmpArray, int left, int right ) {
if( left < right ) {
int center = ( left + right ) / 2;
mergeSort(a, tmparray, left, center );
mergeSort(a, tmpArray, center + 1, right );
merge( a, tmpArray, left, center + 1, right );
}
}
private static void merge( Comparable [ ] a, Comparable [] tmpArray, int leftPos, int rightPos, int rightEnd ) {
int leftEnd = rightPos – 1;
int tmpPos = leftPos;
int numElements = rightEnd – leftPos + 1;
while( leftPos <= leftEnd && rightPos <= rightEnd )
if( a[ leftPos ].compareTo( a[ rightPos ] ) <= 0 )
tmpArray[ tmpPos++ ] = a[ leftPos++ ];
else
tmpArray[ tmpPos++ ] = a[ rightPos++ ];
while( leftPos <= leftEnd )
tmpArray[ tmpPos++ ] = a[ leftPos++ ];
while( rightpos <= rightEnd)
tmpArray[ tmpPos++] = a[ rightpos++ ];
for( int i = 0; i < numElements; i++, rightEnd-- )
a[ rightEnd ] = tmpArray[ rightEnd ];
} 